译者:Carl Cui
在 2024 年年中,The Innovation Game 上线。
The Innovation Game(简称 TIG)是一个基于区块链技术的现代项目,它协调大约 7000 个独立的、不可信的贡献者,针对那些具有重要科学价值的问题,迭代改进其算法。TIG 将这些问题作为挑战发布,例如 SAT 求解、车辆路径规划、二次背包问题、向量搜索和神经网络优化器设计等问题,贡献者提交解决这些问题的算法,算法测试者则被激励采用最高效的算法进行工作量证明,从而形成一种抗干扰的机制,用以奖励表现最优的算法。本质上,TIG 为算法开发创造了一个全新的经济框架。
这些贡献者之间无需相互信任。没有哪个中心机构规定什么才是好的,不过经过独立贡献者 476 次增量提交后,TIG 现在提出的二次背包问题的解决方案,已经超过了 Hochbaum 等人 2025 年在 European Journal of Operational Research 上发表的算法的质量。
TIG 这种协调机制几乎与当今最先进的 multi-agent 框架中采用的设计模式相同,通过分析 TIG,我们可以了解未来集群智能 swarm intelligence 的发展趋势。
1. Generator-Verifie 模式
在 agentic system 设计中,最老且最可靠的模式是将 Generator 和 Verifie 解耦:一个 agent 发起提议,另一个 agent 评估该提议。这种设计随处可见,比如 AlphaCode 的生成再过滤流程,比如宪法 AI 的批评修改循环,比如任何写代码然后运行测试的 coding agent。
TIG 在社会层面上实现了这一模式:
- 贡献者(Generator)将算法实现提交到一个开源仓库
- 算法测试者(Verifiers)针对实际问题运行这些算法并报告结果
贡献者获得的奖励与其算法的采用率成正比,即有多少算法测试者真正选择使用他们的算法。
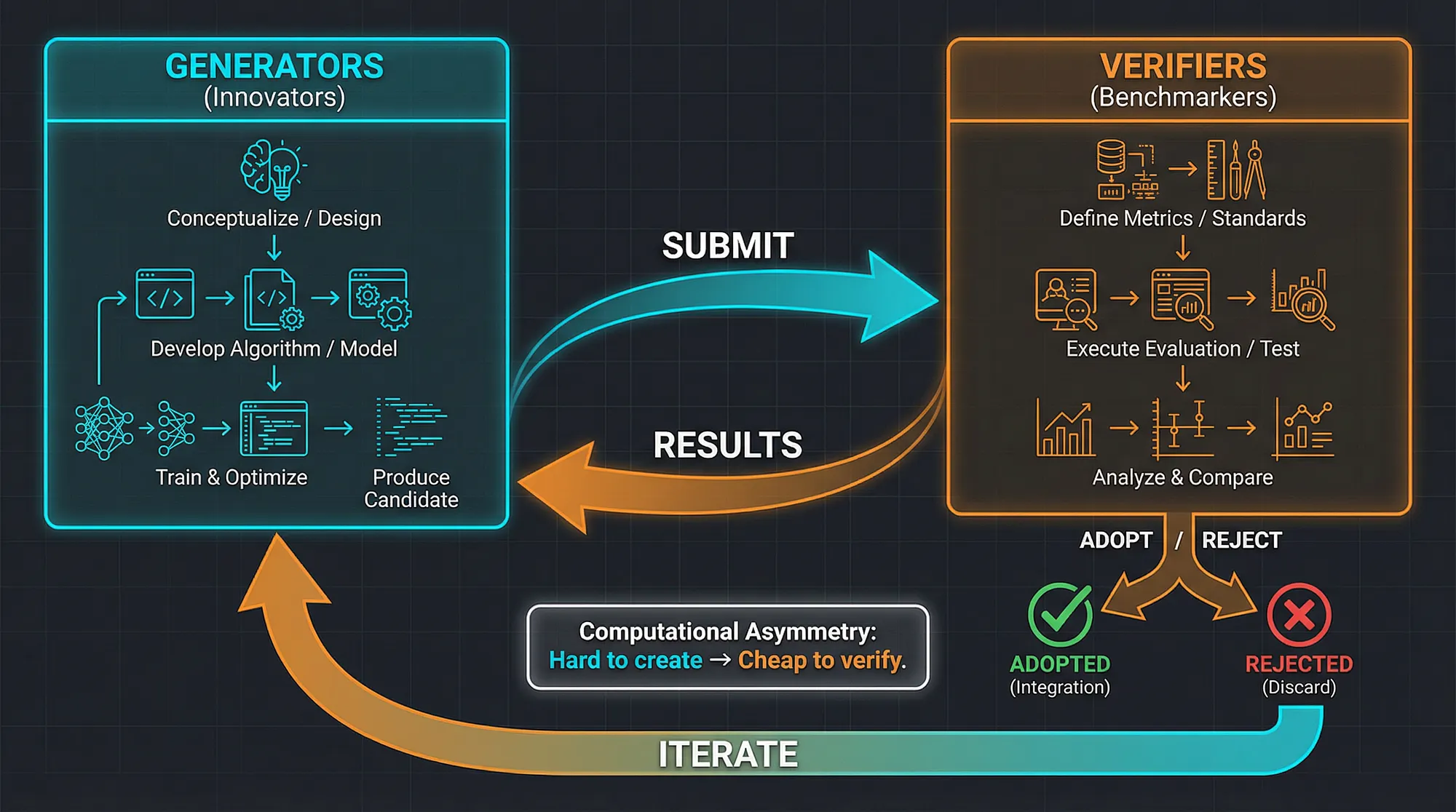
关键问题在于计算上的不对称性:创造一个新算法既困难又昂贵,但验证它在特定实例上是否有效却很便宜。Cynthia Dwork 和 Moni Naor 在 1992 年发表的关于“基于处理定价”的论文中形式化了一种不对称性,和这种不对称性在本质上是一样的,这是工作量证明系统背后的基本思想。
在 agentic 开发中,这种不对称性无处不在:
- 编写正确代码很难,但运行测试套件很“便宜”
- 想出研究假设很难,但用数据集检查它很“便宜”
- 规划一个多步骤的行动顺序很难,但模拟每一个步骤很“便宜”
所以,如果你正在设计一个 multi-agent system,你始终应该问“不对称性在哪里?”:应该把昂贵、有创造力的计算放在一边,把廉价、并行的验证计算放在另一边,让验证者来发挥选择压力 selection pressure 的作用。
2. 最大的难题:无信任协调
Multi-Agent system 中最难的问题是需要在无信任的环境协调共识。1982 年,Leslie Lamport、Robert Shostak 和 Marshall Pease 发表了“拜占庭将军问题”(The Byzantine Generals Problem),这是一个关于分布式参与者如何在部分参与者可能说谎或者失灵的情况下达成共识的思想实验。它成为了分布式系统的理论基础,后来又成为了区块链的理论基础。
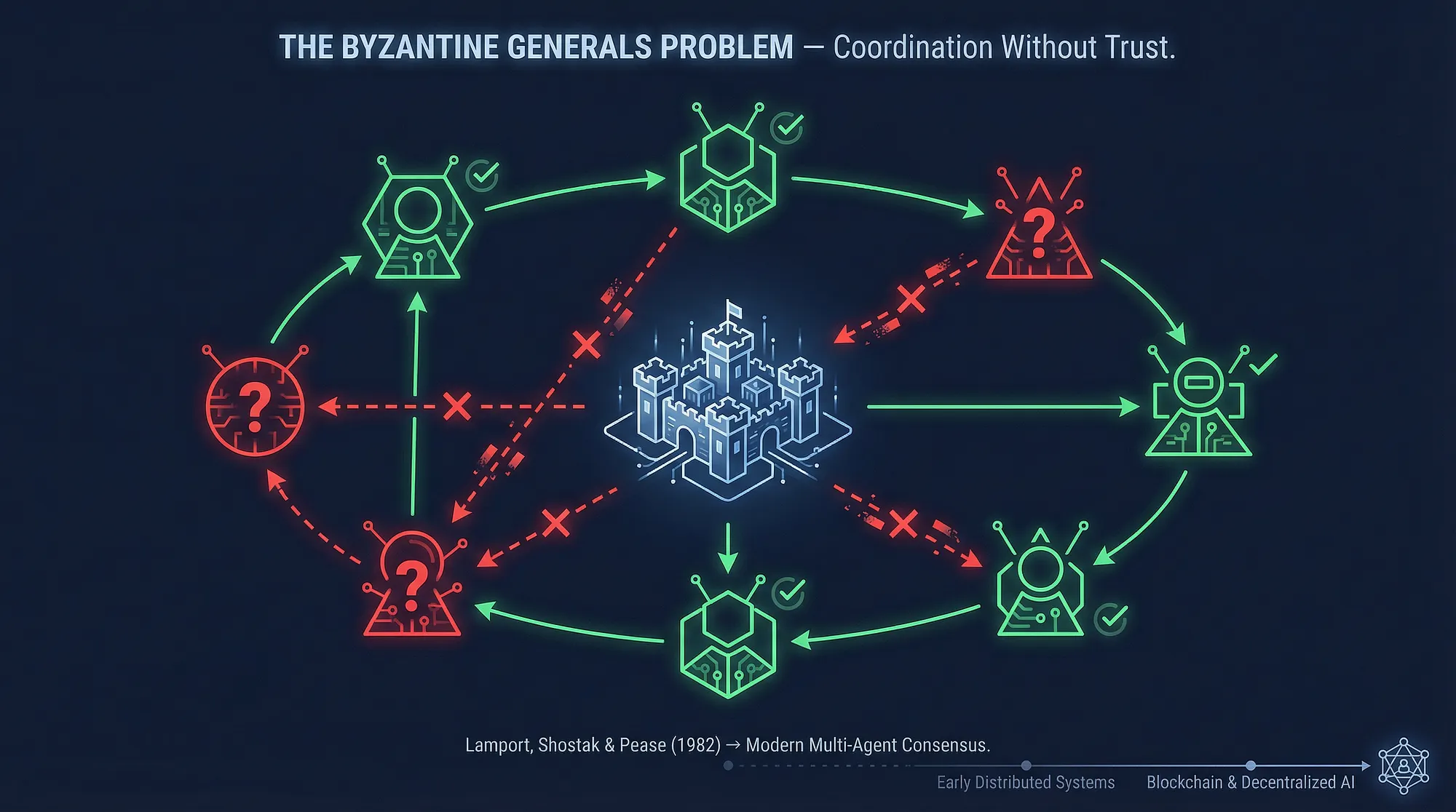
TIG 正是基于这一假设运行:没有任何参与者可以被信任。一个贡献者可能会提交一个剽窃的算法,一个算法测试者可能会报告虚假结果,但系统必须在出现不可靠参与者的情况下产生可靠的结果。这个问题的解决方法是结构性的:
- 提交的内容形成一个 DAG:每次提交都建立在之前提交的基础上,形成一个可审计的改进链
- 验证是分布式的:成千上万的算法测试者独立地测试相同的算法,这使得通过操纵结果来作弊在统计角度变得不现实
- 算法被采用是奖励信号:你无法伪造 7000 个独立参与者的采用情况
当协调多个 LLM agent 时,也会面临同样的信任问题:任何单个 agent 都可能产生幻觉,生成带点小错的代码,或针对 agent metric 而非真正目标进行优化。目前处理这种问题的方法主要有:
- 对多个 agent 的输出进行投票
Majority voting(思维链 Chain-of-Thought 里的自我一致性 Self-Consistency 就是这种思想的应用) - 通过
Judge LLMs来评估其他 agent 的输出 基于执行的验证,实际运行代码,检查输出,与真实情况验证跨 agent 审计,让 agent 互相审查推理链
TIG 表明,在足够大的规模下,你不需要任何单个 agent 可靠,只需要保证协调协议 coordination protocol 足够健壮。这与试图让单个 agent 变得完美无缺的设计理念有着本质区别。你可以从 TIG 论文 上了解这一点。
3. 群体智慧的能量
在1900年左右,Francis Galton 在一次集市上观察到一件奇怪的事情:当 787 个人猜测一头牛的重量时,中位数猜测和真实重量的误差在 1% 以内,这比任何单个专家的估计都要好。这被称为“群体智慧”,后来成为机器学习中集成方法 ensemble methods 的理论基础。
TIG 是这种现象的计算机版本。不需要任何单个贡献者成为菲尔兹奖级别的数学家;相反,通过 476 次渐进式的贡献,每一次都带来了小小的改进或者替代性的方法,使得解决方案的质量不断提升,并超越了现有最先进的技术水平。
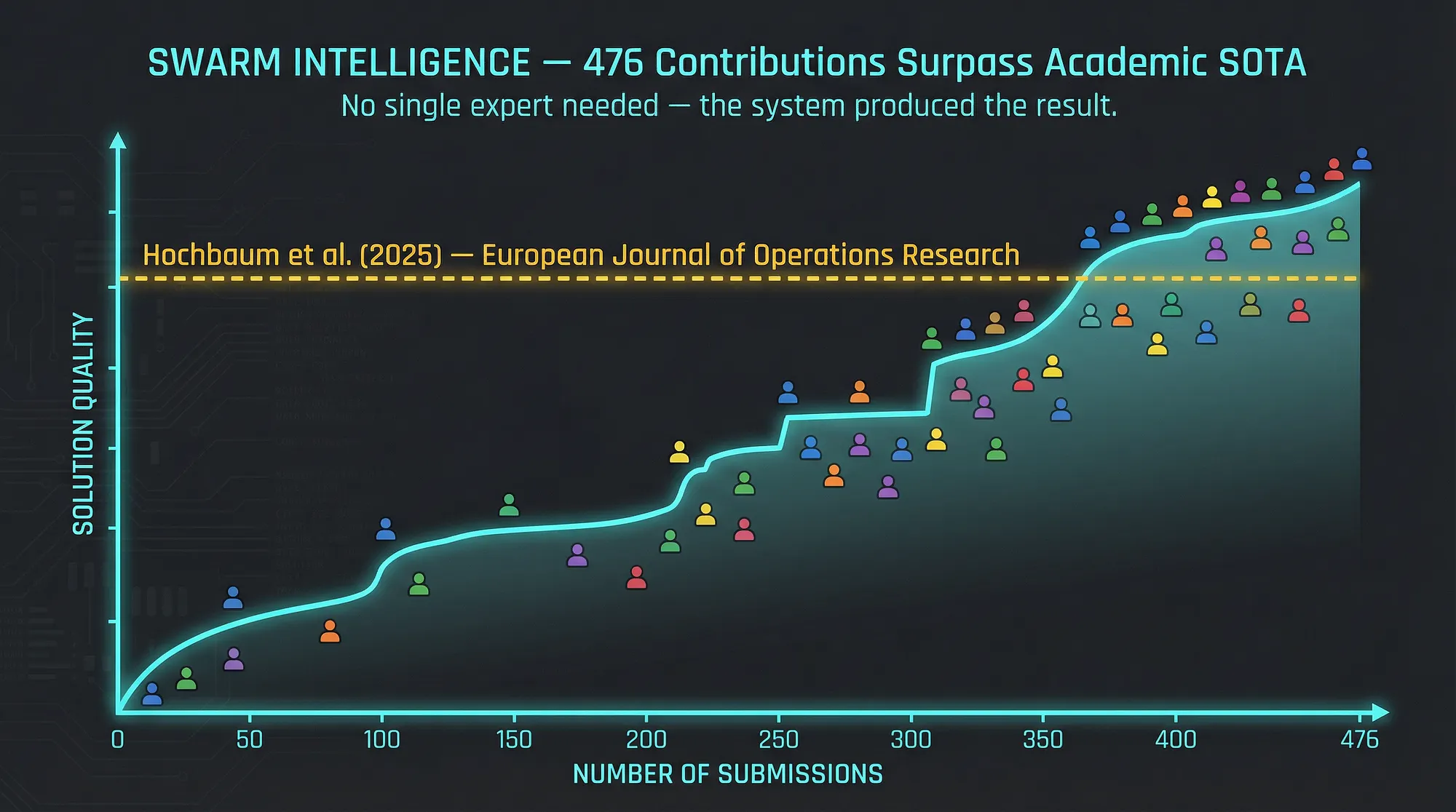
这就是通过迭代选择压力 selection pressure 产生的智能,也是 multi-agent 架构优于单 agent 系统的最有力论据:
- 一个强大的 agent ,它的能力上限是由它的训练数据和推理能力决定的
- 一群有良好 coordination protocol 的 agent 的能力上限,是由他们的共同搜索空间决定的,而这个搜索空间会随着参与者的增加呈组合式增长
在进化生物学里,这就是拉马克进化 Lamarckian evolution 和达尔文进化 Darwinian evolution 之间的区别。拉马克进化是说一个生物体努力让自己变得更好,而达尔文进化是说一个种群探索很多条路,然后选择机制会将最好的那一批保留下来。
在模仿达尔文模式的 agentic systems 中,多个 agent 提出不同的解决方案,最后由稳健的适应度函数 fitness function 选出最佳方案,这样的系统在处理开放式问题时,会比单个智能体不断循环试错的方法表现得更出色。
4. 提交链作为 Agentic Memory
TIG 一个最优雅的架构决策就是改进是链式的:每次新的提交都会看到当前的最佳方案,并在此基础上进行改进。
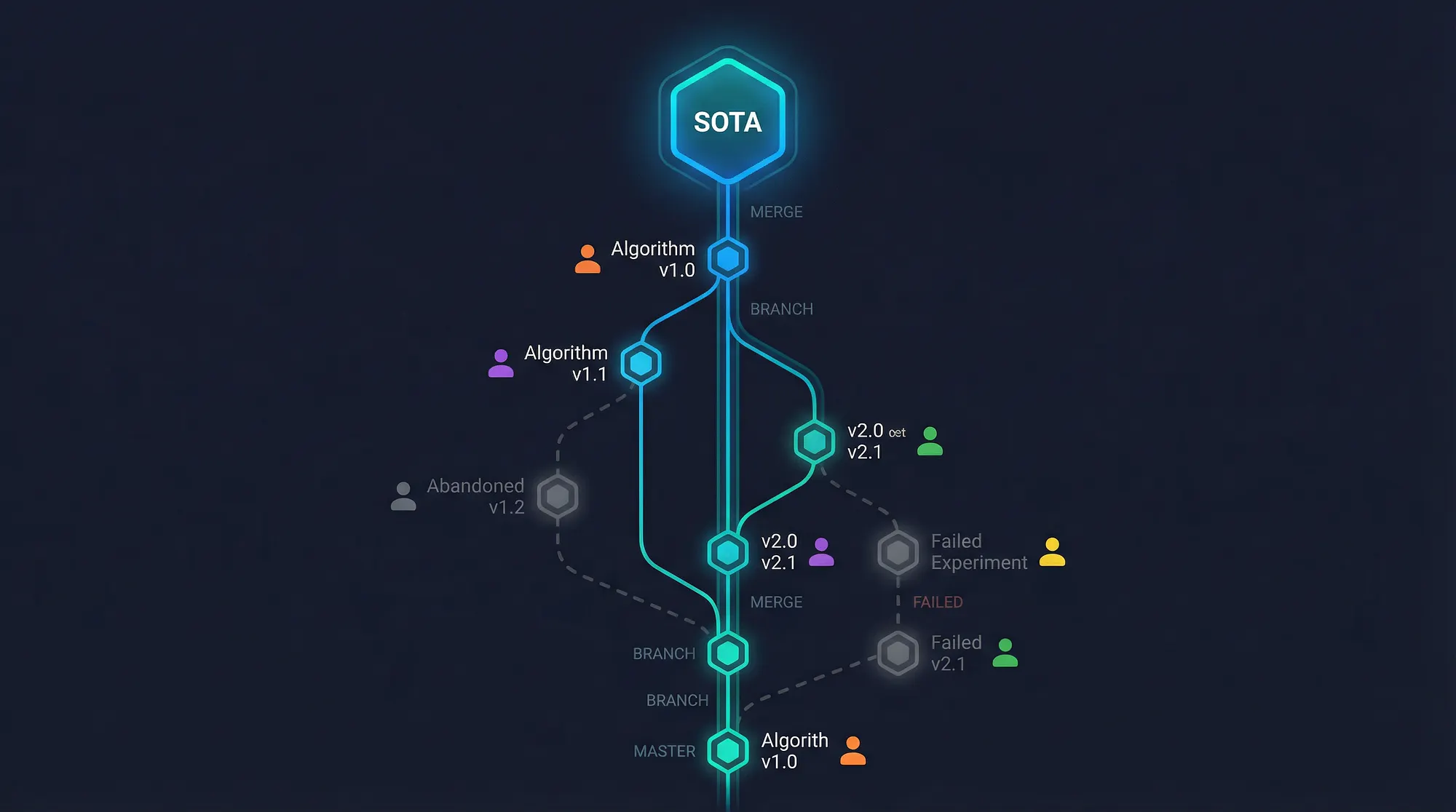
这样就产生了像复利一样的叠加效应,但这是针对算法质量的。在 agentic systems 中,这相当于持久共享内存的概念:
- SWE-bench 风格的 agent 会维护一个不断迭代更新的代码库
- AutoGPT 风格的循环会将发现的信息记录下来,为下一步操作提供参考
- Multi-agent 辩论系统在多轮辩论中逐渐积累起更精确的观点
- Voyager(英伟达公司推出的 Minecraft agent)会建立一个跨回合 episode 的技能库
提交链本身是最有价值的成果,而不是某个人的贡献。476 个提交构成的 DAG 就是知识,它编码了整个搜索历史:尝试过什么、什么有效、什么无效。这意味着结构化记忆和 agent 输出的版本控制对于保持完整的轨迹至关重要。之后的 agent(或同一 agent 的未来迭代)可以从失败的方法和成功的方法中学到同样多的东西。
5. 通过奖励机制促进 agent 协作
如果没有金钱激励,开放式协作就无法与资金充足的封闭式协作进行大规模竞争。在 Agentic AI 中,这直接就关系到奖励机制的设计,这是你需要做的最重要的架构决策。
TIG 的奖励机制非常精妙:
- 贡献者获得的奖励与其算法被采用的程度成正比
- 这是基于结果的,而不是基于努力的:你不会因为提交代码而获得报酬,而是因为提交了真正更好的代码而获得报酬
- 双重许可模式(开放源代码用于公共资源,商业许可用于获取收入)在为系统提供资金的同时,也保持了知识的流动
将其与当前 agentic systems 中的奖励信号 reward signals 进行比较:
- 任务完成情况:agent 是否完成了任务,二元的,粒度过于粗糙
- 测试通过率:有所改善,但可以被操纵(agent 学会编写简单的测试)
- 人工反馈:黄金标准,但成本高昂且无法扩展
- LLM 作为裁判:可扩展,但引入了裁判的偏见
TIG 基于算法采用率作为奖励的方式是一种基于市场的适应度函数 fitness function。它之所以能应对不被信任的贡献者,是因为它汇集了成千上万参与者的独立决策,每个参与者都在优化自己的表现。这与经济学中的预测市场 prediction markets 密切相关,罗宾-汉森(Robin Hanson)等经济学家的研究表明,预测市场机制比专家小组更能有效地汇总信息。
说白了,最可靠的奖励信号,是来自分散的、独立的评估,而不是集中的评判。如果你能设计你的系统,让“好的产出”是由下游的采用程度或实用性来决定,而不是由一个单一评分者来决定,你就能得到更可靠的收敛性。
6. AI Agent 作为创新者
这是未来智能代理开发真正有趣的地方。目前,TIG 的创新者大多是人类(有些可能使用人工智能辅助编码),但该协议与代理无关,它评估的是产出,而不是来源。

一个足够强大的 coding agent 完全有可能做到:
- 在 TIG 的开放源代码库中观察当前的 SOTA 算法
- 分析问题结构并识别潜在的改进点
- 生成算法改动作为候选
- 对算法进行自我测试
- 提交表现最好的算法版本
这恰恰就是“自动研究”系统想要做的事情,而 TIG 也提供了一个现成的评估基础设施给它。
我们正接近一个世界:
- 人类和 AI agent 在同一个协议中竞争与合作
- 选择压力 selection pressure 对它们没有区别
- 系统的输出质量由协调架构决定,而非参与者的本质
这是混合群智能 hybrid swarm intelligence,而 TIG 可能是第一个证明这套体系已经能用的生产系统。
写在最后
译者:人类与 agent 协同工作,基于同样的选择压力,想想挺悲观的,因为我不觉得人类的学习能力可以媲美人工智能。这样的协作系统正在被设计出来,或者干脆已经走进了现实,TIG 就是例子。或许这也是当下北美计算机行业大面积裁员潮的根本原因。
原文链接
What Happens When 7000 Agents Tackle the Same Hard Problems?