译者:Carl Cui
开源模型现在可以处理大量日常工作,对于很多像编码、写作、自动化和 AI Agent 的任务来说,本地部署的 LLM 可以替代云端 LLM。并且,每一次发给云端 LLM 的请求都会离开你的电脑,经公共网络发送到云端服务器。对于专有代码库、敏感的原型或者受监管的行业来说,这是不可接受的。本地运行推理服务可以避免数据外流,对于很多团队来说,数据主权本身就值得考虑本地 LLM。
目前,Claude Code 重度用户每月需要支出 100 ~ 200 美元。按照当前的 API 费率,通过 Cline 或 Kilo Code 使用 Claude Sonnet 4.6,每小时大约需要 3 ~ 8 美元。如果你正在运行代理群、大量迭代或者大量子任务,把其中那些日常的任务交给本地模型可以节省大量开支。
除了介绍 7 种本地可以部署的模型,作者也介绍了如何配置 Claude Code 和 Codex,匹配的 Nvidia 和 Mac 硬件,以及部署的注意事项、故障模式和有关的利弊权衡,比如处理延迟、资源需求、API 兼容性、生成代码的可靠性和指令遵循质量等等。
硬件匹配表
本地能够运行的模型受限于拥有的硬件。如果你使用的是 MacBook Air,评估一个 70B 模型是没有意义的。

大多数模型在 Q4_K_M 量化后可以维持其 MMLU 跑分,与全精度相比,分数差距在 1 到 3 分以内。不过,这种退化程度因任务而异,像多步数学推理这样的专业任务,退化程度可能超过 5%。建议从 Q4_K_M 开始。如果你在目标任务上感觉精度不够,可以切换到 Q5_K_M。
1. Qwen3 - 适合编码和多语言 AI Agent
- 大小:1.7B,7B,14B,32B,72B,235B MoE
- 硬件:RTX 4060 → Mac M4 → Workstation
本文列出的模型中,Qwen3-7B 的 HumanEval 跑分(76.0)是所有 8B 参数下模型中最高的,比 Llama 3.3 的 72.6 高出 3.4 分。在四个主要语系中,Qwen3 7B 的多语言支持能力最强,在中、日、韩语方面表现尤为突出,在英语方面的表现也很强劲。
32B 稠密模型是单块 24GB GPU 上支持实际 agentic coding 的最佳选择。到 2026 年 3 月,Qwen 3.5 和 GLM-4.7-Flash 是最强的 35B MoE agentic and coding 模型,它们在 24GB 的显存或者统一内存设备上运行良好,能够自主完成复杂任务。
1.1 llama.cpp 设置
# Download Qwen3 32B Q4_K_M via llama.cpp
./llama-cli \
-m qwen3-32b-instruct-q4_k_m.gguf \
--server \
--host 127.0.0.1 \
--port 8080 \
--ctx-size 32768
# Point Claude Code at local server
export ANTHROPIC_BASE_URL=http://127.0.0.1:8080
export ANTHROPIC_API_KEY=sk-dummy-local
# Claude Code now routes to your local Qwen3 instance
claude
1.2 注意事项
Qwen3 的请求参数规格与标准 OpenAI API 略有不同,这会导致一些假设严格遵循 OpenAI 格式的 agent 框架出现失败。集成之前,需要测试兼容性。
1.3 故障说明
在 7B 版本上,超过 24K 个 token 后,长文本质量下降。多步推理的可靠性与 32B+ LLM 相比明显下降。
2. DeepSeek-Coder V3 / DeepSeek V3 (DeepSeek) — 最适合纯代码任务
- 大小:7B, 14B, 33B, 236B MoE (V3 full)
- 硬件:RTX 4070 (14B) → Workstation (full 236B MoE)
DeepSeek V3 有 235B 参数(22B 活跃参数),并且专门针对代码和 agent 任务进行了优化。它的 MoE 架构意味着在推理过程中,活跃的参数数量远低于总数,你可以用 22B 规模的计算资源,获得 235B 规模的认知能力。
14B 稠密模型可轻松运行在单个 16GB GPU 上,并且在 HumanEval 和 SWE-bench 子集上的表现优于许多上一代的 34B LLM。对于代码生成、代码审查、代码重构、测试编写这样的工作负载,该系列比文中任何其他 LLM 都更稳定。
2.1 Ollama 设置
# Pull DeepSeek-Coder V3 14B
ollama pull deepseek-coder-v3:14b
# Serve as OpenAI-compatible endpoint
ollama serve
# Endpoint: http://localhost:11434/v1
# Connect Claude Code
export ANTHROPIC_BASE_URL=http://localhost:11434/v1
export ANTHROPIC_API_KEY=ollama
claude
2.2 注意事项
非代码任务的指令遵循能力明显弱于代码任务。如果你正在处理混合的工作负载(编码、协作和工具使用),DeepSeek-Coder V3 在编码方面会处理得很好,但在其他方面就会令人失望。把它当作专门的编程人员来用,而不是一个通用的代理。
2.3 故障说明
7B 和 14B 版本输出的 Markdown 格式有时不一致。在保存输出的内容之前,先对内容进行审查。
3. Llama 3.3 (Meta) - 最佳生态系统和最全面的工具支持
- 大小:8B,70B
- 硬件:RTX 4060 8GB (8B Q4) → Mac M3/M4 36GB+ (70B Q4)
Llama 3.3 有最大的开放权重生态系统,拥有广泛的社区微调版本和丰富的工具支持。对大多数开发者来说,Llama 3.3 8B 是总体上最好的起点。
Llama 在生态系统而非基准性能方面领先的原因,在于Meta 的模型发布节奏和与 OpenAI 兼容的 API 格式,让它成为每项微调工作、每个优化库和每个添加本地模型支持的代理框架的默认目标。当一个新工具添加本地 LLM 支持时,Llama 就是它测试的第一个模型系列。
这意味着集成时遇到的意外情况会减少。出现 silent format failure 的情况会减少。使用工具时,schema 不匹配的情况也会减少。
3.1 Docker Model Runner 设置
# Pull and run Llama 3.3 8B via Docker Model Runner
docker model pull ai/llama3.3:8B-Q4_K_M
docker model run ai/llama3.3:8B-Q4_K_M
# OpenAI-compatible endpoint
# http://localhost:12434/engines/llama.cpp/v1
# Claude Code integration
export ANTHROPIC_BASE_URL=http://localhost:12434/engines/llama.cpp/v1
export ANTHROPIC_API_KEY=sk-dummy-local
claude
3.2 注意事项
Llama 3.3 70B 版本是适合实际工作的,但 Q4 版本需要 40GB 以上的显存或统一内存,这意味着你需要一台 Mac M3 Max(48GB)或者 M4 Max(128GB)的电脑,或者在 Linux 系统上使用多 GPU 配置。而 8B 版本则适合日常任务,配置要求不高,但在多步骤推理任务上,8B 和 70B 之间的差距比参数数量差异所显示的要大。
3.3 故障说明
在 8B 版本中,上下文窗口处理在超过 16K 个 token 后会下降。限制上下文范围,或者在你代理框架中使用滑动窗口策略。
4. Phi-4 (Microsoft) - 最适合资源受限环境
- 大小:Phi-4-mini (3.8B), Phi-4 (14B), Phi-4-reasoning (14B)
- 硬件:任何具有 4GB 系统内存的硬件(mini)→ RTX 4060(14B)
Phi-4-mini(3.8B)是低配置硬件上唯一靠谱的选择。Phi-4-mini 和 Phi-4 14B 是不同的模型,有自己独立的基准测试配置。它的设计目标是在参数数量相对较少的情况下仍追求高性能,主要针对资源受限的设备。
Phi-4-reasoning 和 Phi-4-reasoning-plus 在数学和科学推理方面,特别是在博士级别的问题上,大多数基准测试中都超过了 OpenAI o1-mini 和 DeepSeek-Distill-Llama-70B。但这并不是关于通用能力的声明,而是在结构化推理任务上的一种具体且真实的优势。
对于 CI/CD 管道、边缘部署、物联网设备,或者任何你需要用硬性内存上限进行大语言模型推理的场景,文章里其他产品都不能和 Phi-4-mini 的性能资源比相媲美。
4.1 CI/CD 集成设置
# Phi-4-mini in llama.cpp for CI pipeline
./llama-server \
-m phi-4-mini-instruct-q4_k_m.gguf \
--port 8080 \
--ctx-size 8192 \
--n-gpu-layers 0 # CPU-only for CI runners
# Use in GitHub Actions
- name: AI Code Review
run: |
curl http://localhost:8080/completion \
-d '{"prompt": "Review this diff for security issues: '"$(git diff HEAD~1)"'",
"max_tokens": 512}'
4.2 注意事项
在复杂的、需要多步骤推理的任务上,3.8B 版本的表现问题会比较明显,它的准确率比其他 7B 或 8B 的模型明显下降。较小的模型对量化损失可能更敏感,如果你在目标任务上发现准确率不足,可以评估一下 Q5_K_M 这个量化版本。
4.3 故障说明
在长、多段的 system prompts 情况下,小模型上的指令遵循不一致。将系统提示保持在 200 个 token 以内,并将任务指令尽可能设计为单目标任务。
5. Mistral Small 3 / Mixtral 8x7B (Mistral AI) - 最适合吞吐量
- 大小:Mistral Small 3 (7B dense), Mixtral 8x7B MoE
- 硬件:RTX 4060 8GB (Small 3) → RTX 4090 24GB (Mixtral 8x7B)
当吞吐量最为关键时,Mistral Small 3 7B 获胜,以其推理速度和强大的指令遵循能力而闻名。
如果你的瓶颈是每秒处理的 token 数量,而不是推理深度,比如需要处理大量文档的实时摘要、并行代理工作、实时响应生成,那么在 GPU 成本方面,Mistral Small 3 比这个级别中其他任何模型都能提供更高的吞吐量。在一块 RTX 4060 显卡上,Mistral Small 3 Q4 的速度可以达到每秒 50 到 80 个 token,而同一块硬件上的 Llama 3.3 8B 只能达到每秒 40 到 60 个 token。
5.1 注意事项
Mixtral 8x7B 需要加载完整的 MoE 权重矩阵,即使推理时只有一小部分是活跃的,这也需要 24 ~ 48GB 的系统内存。在显存 24GB、系统内存 64GB 的机器上,可以卸载部分任务,但被卸载的层会引入延迟。在部署之前,先在你的实际硬件上进行基准测试。
5.2 故障说明
Mistral 模型用的聊天模板 chat template 格式和 Llama 有点不一样。大多数框架都能自动处理好这个差异,但是如果你手动用 API 来拼接提示词,要是模板用错了,那指令的理解能力就会下降。你需要检查 tokenizer_config.json 这个文件,并且明确指定要用的聊天模板。
6. GLM-4.7 (Z.AI / Zhipu AI) - 最适合多模态和长上下文代理工作
- 大小: GLM-4.7-Flash (9B), GLM-4.7 (35B MoE)
- 硬件:RTX 4070 16GB (Flash) → RTX 4090 / Mac M4 Max (35B MoE)
截至 2026 年 3 月,GLM-4.7-Flash 是最强的 35B MoE 代理和编码模型,可用于需要多模态输入的代理工作流程。
GLM-4.7 能原生处理图像和文本混合的输入,这意味着那些处理截图、图表或 UI 模板的自动化工作流,可以在本地直接处理这些任务,而不用另外加载一个专门处理图像的模型。
Z.AI 的 GLM-5 和 GLM-4.7 仍然很有用,但是一旦你在真实的智能体循环里测试它们,而不是在孤立的代码提示里测试,它们的优点就不那么明显了。Flash 版本(9B 活跃参数)才是实际的入门选择。完整的 35B 的 MoE 是真正能让多模态能力与众不同的地方。
6.1 注意事项
GLM-4.7 中的信任评分校准方式与其他模型不同,它更有可能拒绝涉及安全相关代码的请求,即使其意图是合法的。为渗透测试、漏洞扫描或安全审查任务的 system prompts 添加明确的上下文。
6.2 故障说明
不同模型的工具兼容性各不相同。在部署前,请使用代理框架进行明确测试。在参数规模相同的情况下,Flash 模型的兼容性低于 DeepSeek-Coder V3。
7. Qwen3.5 (Alibaba) - 2026 年最适合实际代理工作负载的模型
- 大小:7B, 14B, 32B, 72B, 235B MoE
- 硬件:RTX 4070 (14B) → Mac M4 Max (72B) → Workstation (235B MoE)
截至 2026 年 3 月,Qwen3.5 是功能最强的一个智能代理和编程模型,它能够在 24GB 显存的设备上,同时满足编程可靠性和长文本处理的需求。
对于日常开发任务,Qwen3.5 的 9B 模型,在紧凑性和性能之间取得了最好的平衡。32B 的稠密模型可以满足实际的智能代理任务:多文件重构、复杂的调试会话、需要掌握大型代码库完整上下文的架构级推理。
7.1 llama.cpp 设置
# Build llama.cpp with CUDA support
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j \
--target llama-server
# Serve Qwen3.5 32B MoE
./llama.cpp/build/bin/llama-server \
-m qwen3.5-32b-instruct-q4_k_m.gguf \
--host 127.0.0.1 \
--port 8080 \
--ctx-size 65536 \
-ngl 40 # layers on GPU
# Claude Code → local Qwen3.5
export ANTHROPIC_BASE_URL=http://127.0.0.1:8080
export ANTHROPIC_API_KEY=sk-local-dummy
# Add to ~/.claude.json to persist:
# "primaryApiKey": "sk-local-dummy"
claude
7.2 注意事项
长文本处理是 Qwen3.5 的一个特点,具体支持多少长度的上下文窗口,要看你在 Hugging Face 上查到的那个模型的说明。跟普通精度比起来,Q4_K_M 会减少一些上下文窗口的配置。
7.3 故障说明
要让 235B MoE 实际上能达到不错的推理速度,就需要多节点配置,或者使用 NVLink 连接的双显卡配置。如果在单张显卡上运行,哪怕是 4090,整个 MoE 的速度也慢得无法进行交互使用。
选择建议
不需要所有任务都使用云端 LLM。对于很多编码、写作、自动化和代理任务,本地 LLM 现在可以可靠地进行处理。
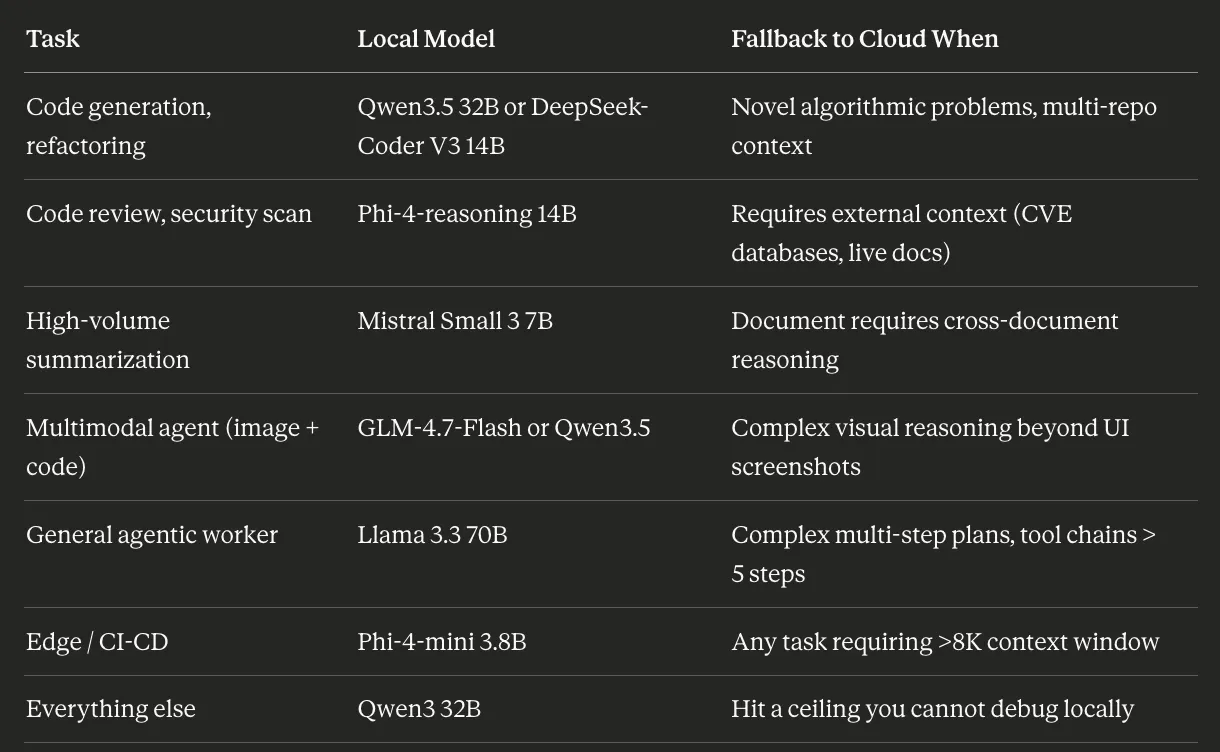
最高产的那帮开发者是这么安排的:用终端 agent 来自动化任务,用 IDE 代理来处理日常开发工作,遇到那些不需要顶尖能力的任务,就用本地模型来处理。目的并不是要消除云端 LLM 的使用。而是要让云端 LLM 的使用变得有针对性:只在真正复杂的任务中使用,而不是默认为所有任务都使用。
这里提供一个实际可行的迁移路径:先用 Qwen3 32B 在 Claude Code 里通过 llama.cpp 跑起来。体验一周,看看有什么它搞不定的任务。然后把那些任务都转到云端 LLM。
原文链接
7 Local LLM Families To Replace Claude Codex (for everyday tasks)