作者:Sumit Pandey
译者:Carl Cui
Apache 2.0 许可证,在笔记本电脑上运行,性能超越 20 倍于其规模的模型。
说实话。在 Gemma 2 之后我就没再关注 Gemma 了。不是因为它不好,而是我感觉它很难同中国开源巨头(例如 DeepSeek、Qwen)发布的模型相媲美。Gemma 曾经是那种你在 Kaggle 上试过一次就忘记的模型。今天,Google 彻底改变了这一局面。

图片由 ChatGPT 生成。
Gemma 4 于 2026 年 4 月 2 日发布。Hugging Face 的 CTO Julien Chaumond 用火焰表情符号发布了相关消息,称之为“突发新闻”。当托管全球所有开源模型的平台 CTO 说 Google 重新入局时,你必须关注。
让我来解析发生了什么,为什么这很重要,以及这些基准测试是否站得住脚。
Gemma 4 是什么?
Gemma 4 是 Google DeepMind 最新的开源权重模型系列。基于 Gemini 3 的研究和技术构建,后者是 Google 的专有前沿模型。
四种模型尺寸。四个部署目标:
- E2B(有效 2B 参数):可在手机、树莓派、Jetson Nano 上运行。是的,没开玩笑。
- E4B(有效 4B 参数):稍大的边缘模型。仍可在手机上运行。
- 26B MoE(混合专家,4B 激活参数):尽管总参数量为 25.2B,但推理时仅激活 3.8B 参数。运行速度几乎与 4B 参数模型一样快。
- 31B Dense(稠密模型):旗舰型号。在 Arena AI 文本排行榜所有开源模型中,目前排名第三。
所有四个模型都能处理图像和视频。较小的 E2B 和 E4B 模型还支持原生音频输入:设备端语音识别,无需云端处理。边缘模型的上下文窗口可达 128K token,大型模型可达 256K token。这相当于将整个代码库放入单个提示中。
基准测试数据
以下是实际数据。这些数据来自官方 Gemma 4 模型卡,指令调优变体:
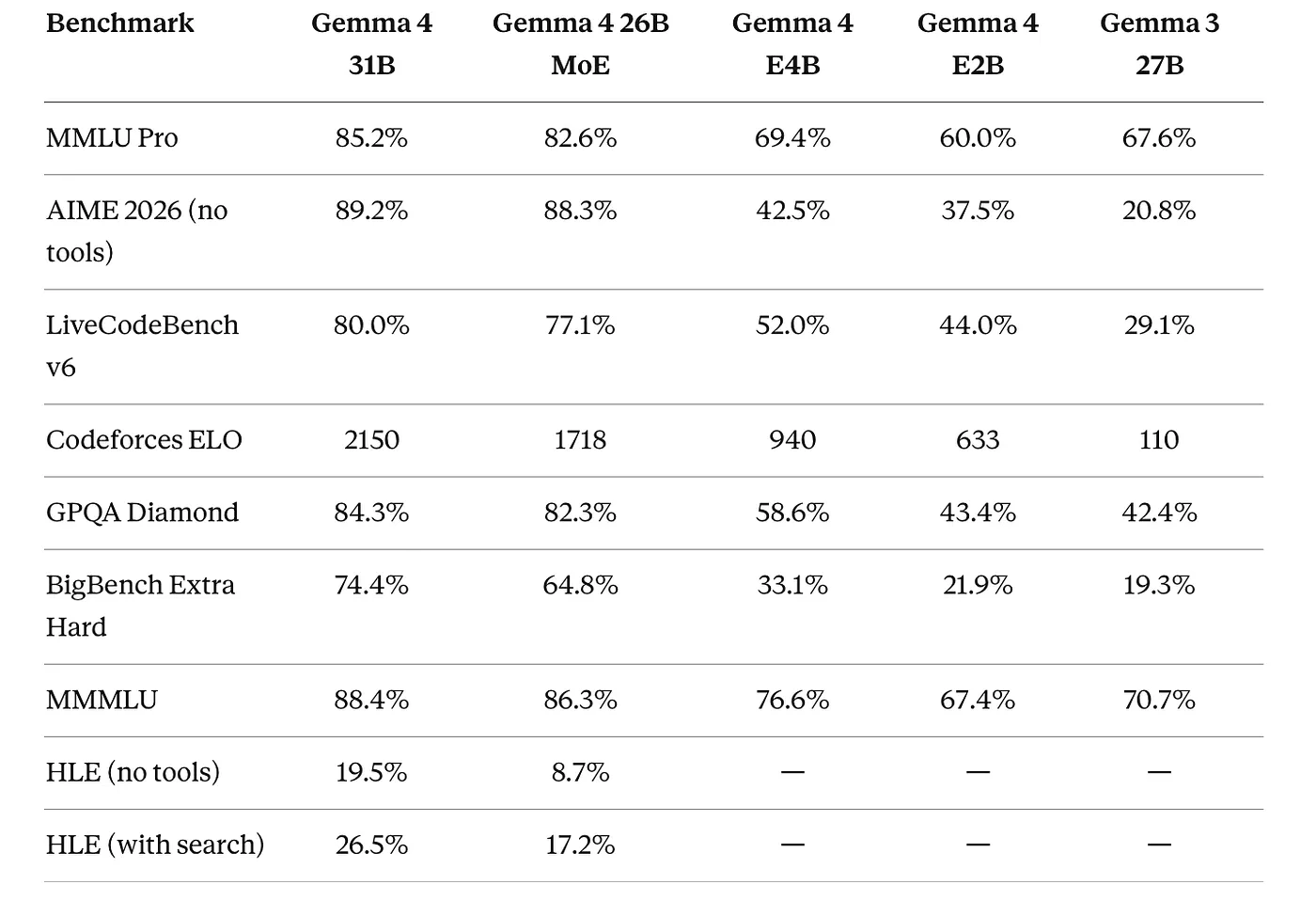
文本基准测试
视觉基准测试
长上下文

让我重点介绍最重要的数据:
- AIME 2026:31B 模型得分 89.2%。这是数学竞赛基准测试。Gemma 3 27B 得分为 20.8%。一代之间性能提升 4 倍。
- Codeforces ELO:31B 模型得 2150 分。作为对比:Gemma 3 得 110 分。编程能力提升惊人。
- LiveCodeBench v6:80.0% 对比 Gemma 3 的 29.1%。几乎翻了三倍。
- GPQA Diamond:84.3%。这些是博士级别的科学问题,人类专家得分约 65%。
混合专家模型特别有趣。总参数量 26B,推理时仅激活 3.8B 参数,在 GPQA Diamond 上得 82.3% 分。它以接近 4B 参数模型的速度运行,却提供接近 31B 参数模型的智能水平。
Gemma 4 与前沿模型对比如何?
孤立的数据没有意义。让我将 Gemma 4 与大家实际使用的专有模型进行对比:Claude Opus 4.6、GPT-5.2 和开源巨头 Kimi K2.5。
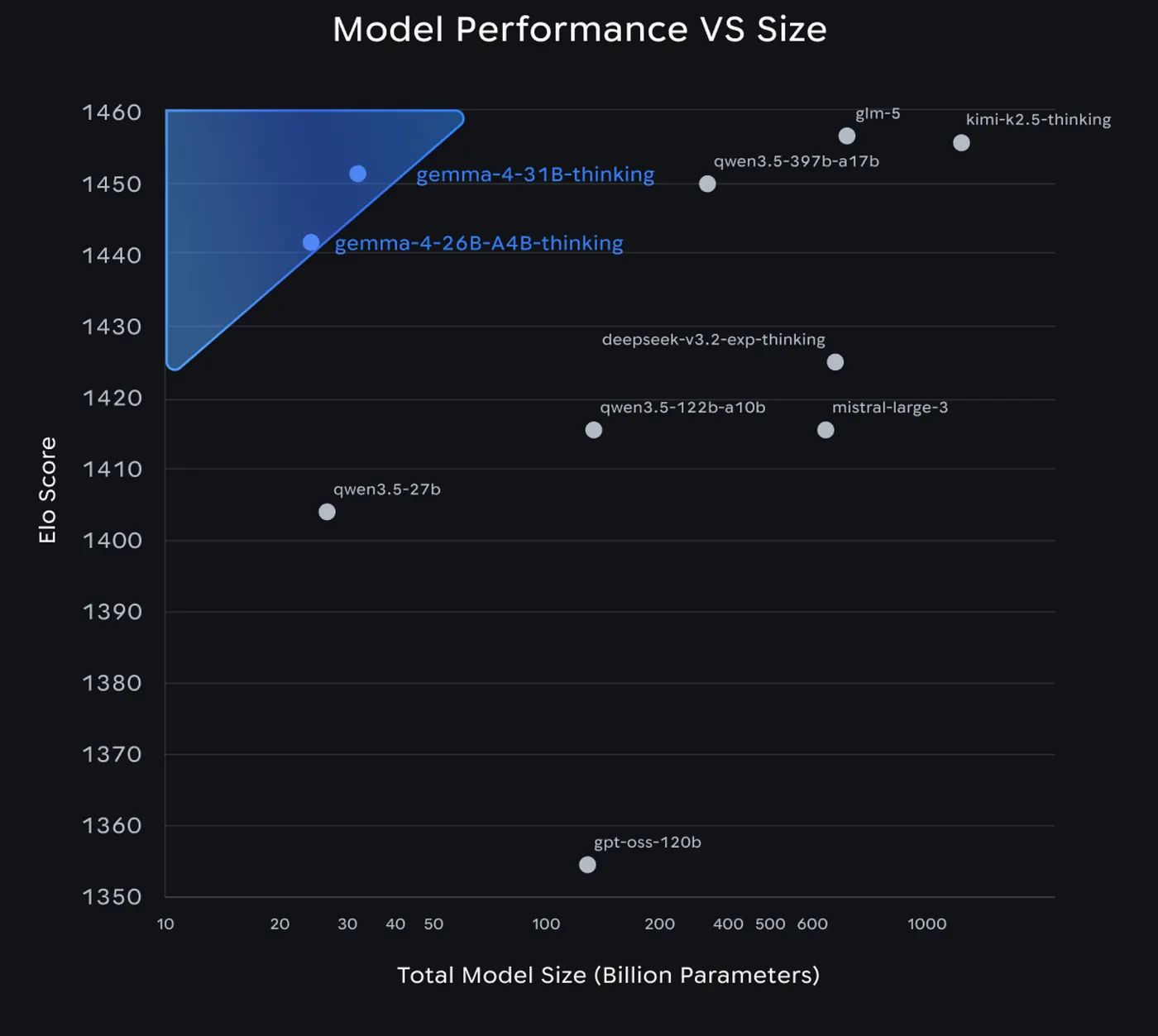
重要提示:这不是完全对等的比较。Gemma 4 31B 有 31B 参数。Claude Opus 4.6 和 GPT-5.2 是参数未公开的专有模型,几乎肯定有数百 B 参数甚至更多。Kimi K2.5 有 1000B 总参数(激活 32B)。Gemma 4 能与这些模型相提并论,这本身就是故事。
推理能力:GPQA Diamond(博士级科学问题)
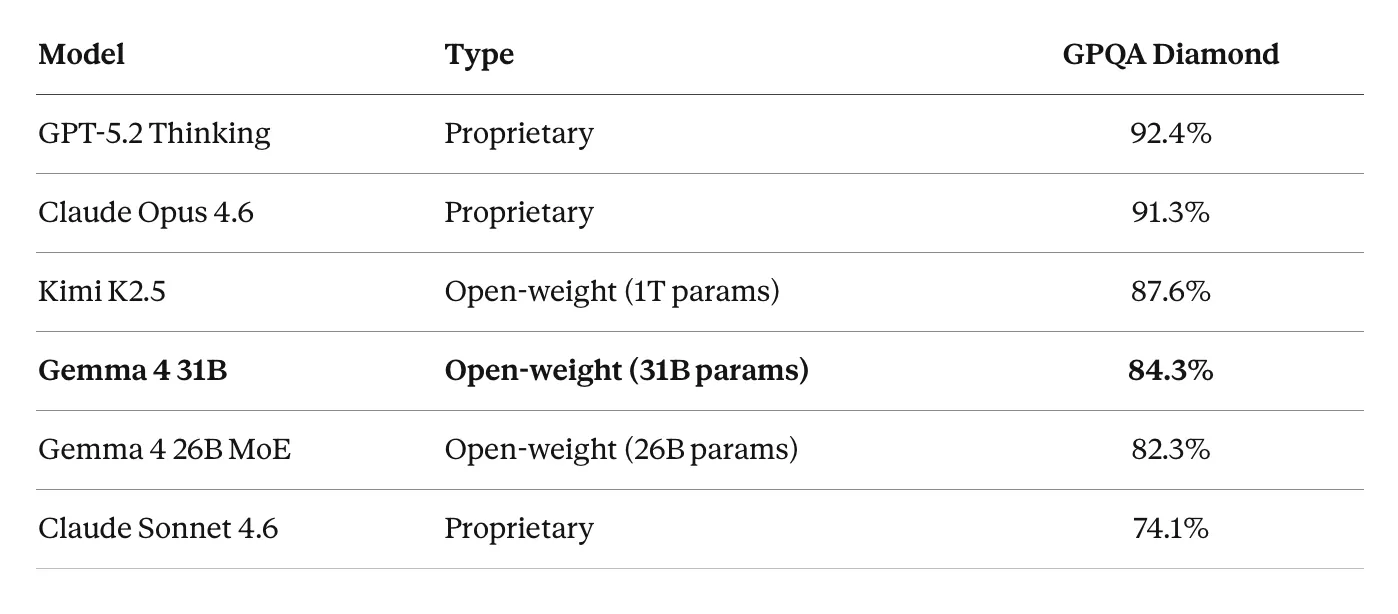
Gemma 4 31B 在博士级科学推理上得 84.3% 分。这比 Claude Opus 4.6(91.3%)和 GPT-5.2(92.4%)低约 7-8 个百分点。但关键是:那些是在服务器集群上运行的大型专有模型。Gemma 4 可以在你的笔记本电脑上运行。而且它比 Claude Sonnet 4.6(74.1%)高出 10 多个百分点。
数学:AIME(竞赛数学)
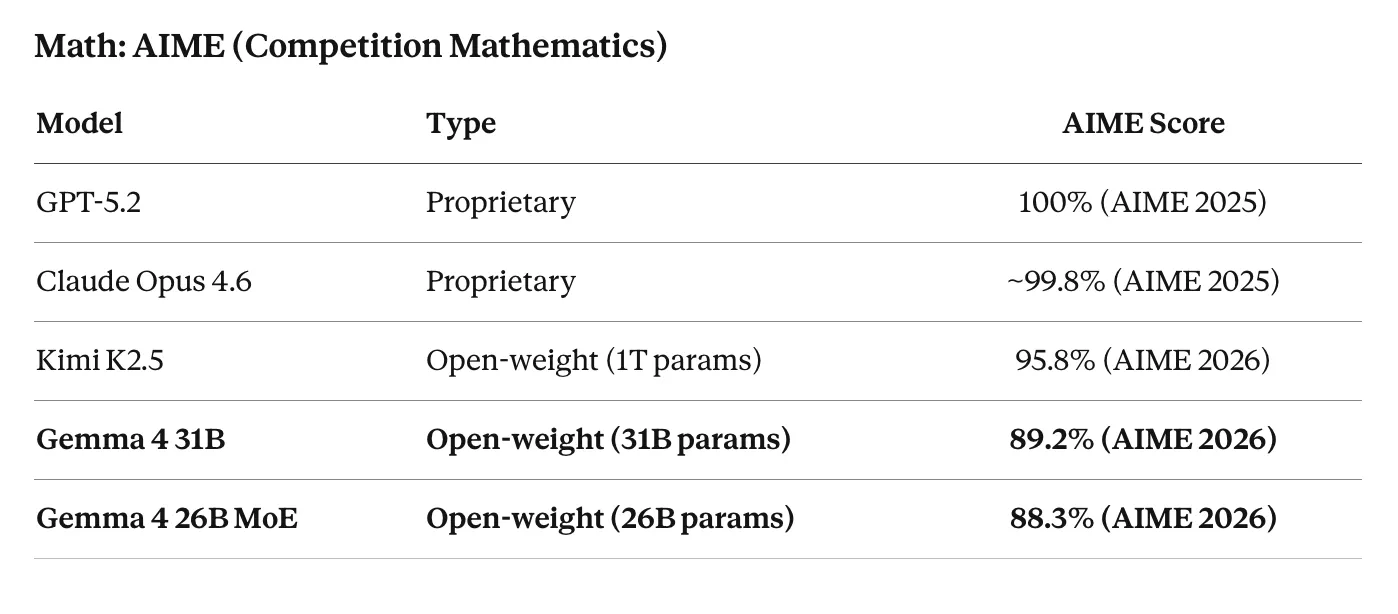
注意:Gemma 4 报告的是 AIME 2026(更难的题目集),而大多数其他模型在 AIME 2025 上评估。即使考虑这一点,一个 31B 参数模型在竞赛数学上获得 89.2% 的分数是显著的。GPT-5.2 和 Claude Opus 4.6 获得接近完美的分数,但它们是专有模型,计算量高出几个数量级。Kimi K2.5 得 95.8%,但总参数量为 1000B。
知识:MMLU Pro(研究生水平问题)
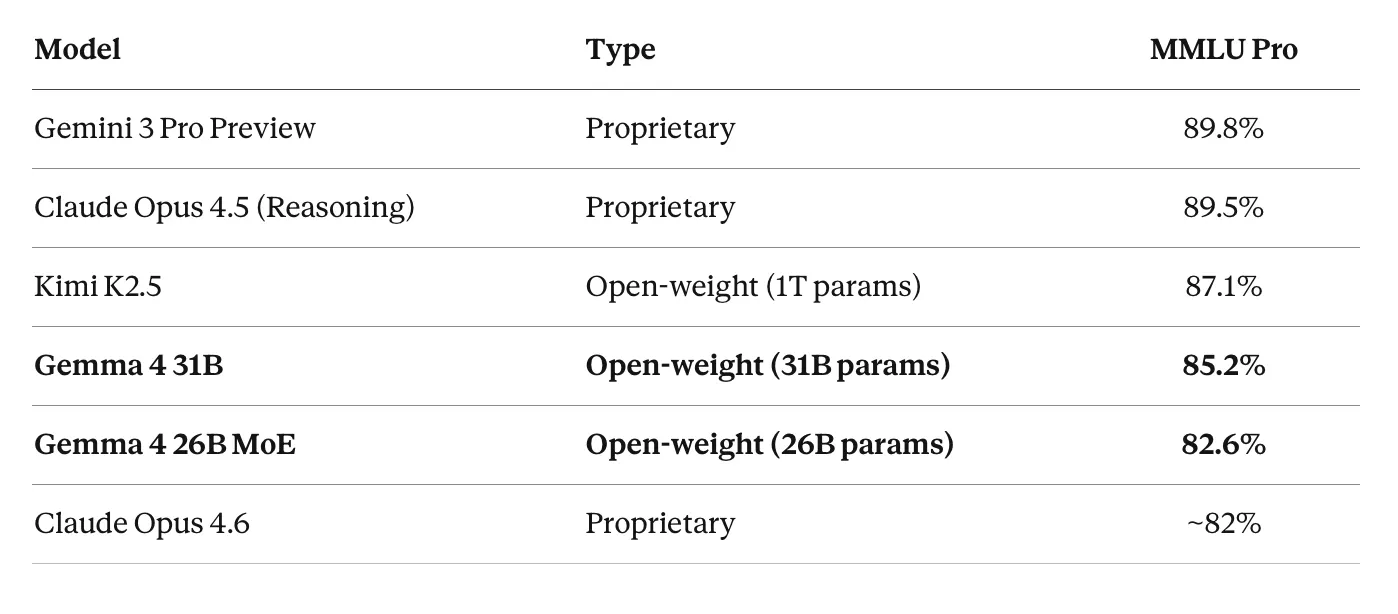
Gemma 4 31B 在 MMLU Pro 上得 85.2% 分。这使其与 Kimi K2.5(87.1%)相差不远,尽管总参数少 30 倍。它似乎也与 Claude Opus 4.6 报告的 MMLU Pro 分数(约 82%)相当或略高。
编程:SWE-Bench 和 LiveCodeBench
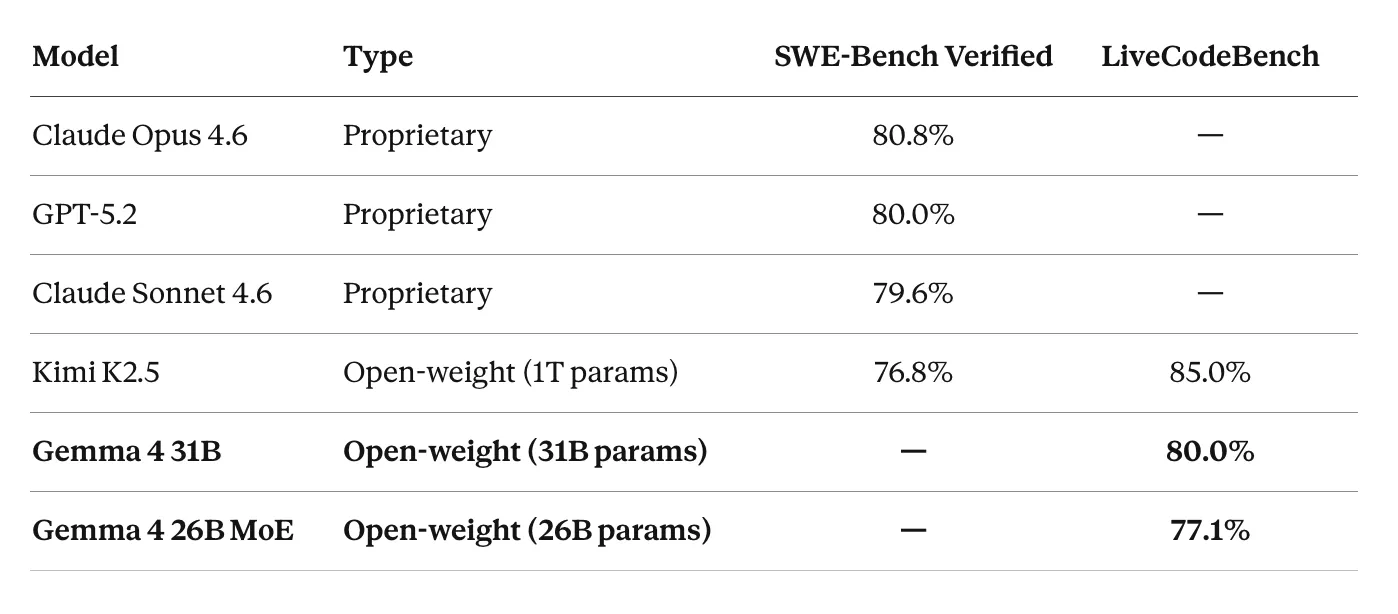
Gemma 4 在 LiveCodeBench v6 上报告 80.0%,Codeforces ELO 为 2150。虽然 SWE-Bench Verified 数据尚未公布,但编码性能显然具有前沿竞争力。LiveCodeBench 分数将 31B 模型置于与 Kimi K2.5 相同的层级,而后者总参数多 32 倍。
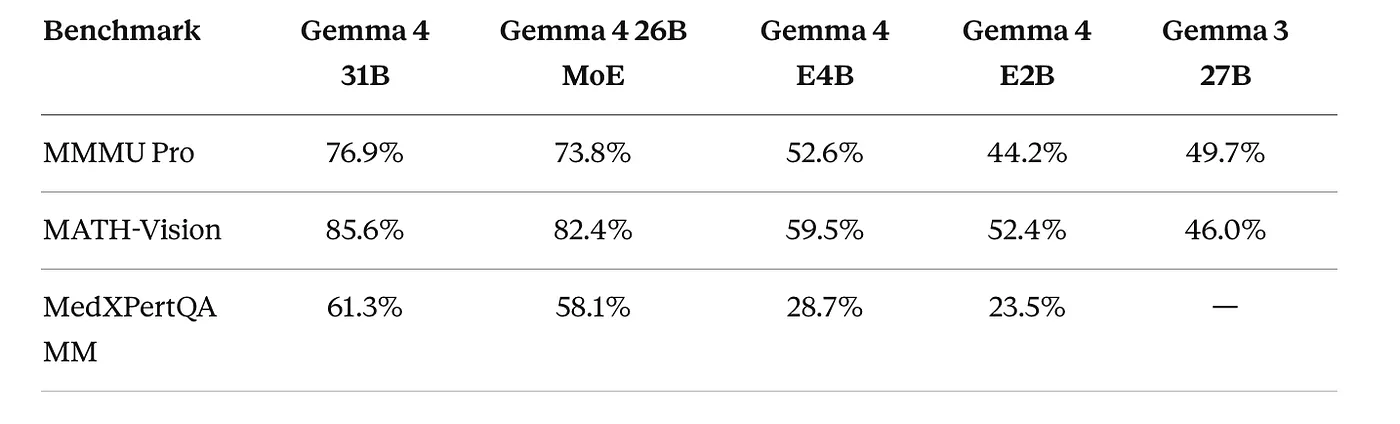
视觉:MMMU Pro(多模态推理)

在多模态视觉推理方面,Gemma 4 31B 与 Claude Sonnet 4.6 基本持平。对于一个 31B 参数的开源模型来说,这是非常出色的表现。
每参数智能表现
以下是真实情况。这是关于效率的表格:
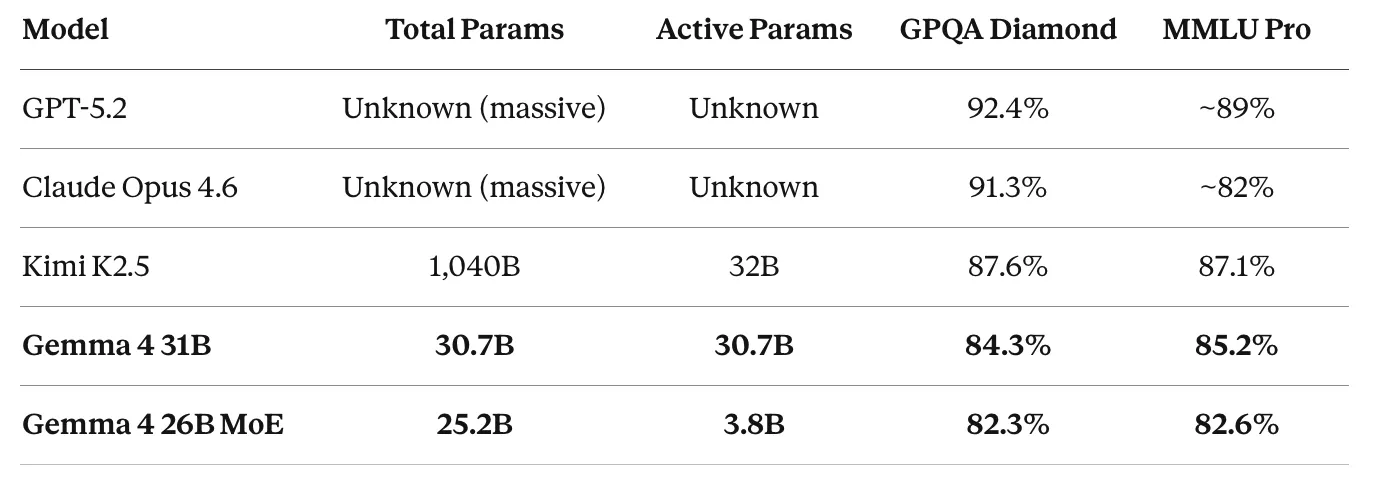
特别关注 26B MoE 模型。它每个 token 仅激活 3.8B 参数。这大约相当于一个小型模型的计算量。它在 GPQA Diamond 上得 82.3%,在 MMLU Pro 上得 82.6%。
Kimi K2.5 每个 token 激活 32B 参数,总参数量 1000B,在 GPQA 和 MMLU Pro 上分别获得 87.6% 和 87.1% 的分数。虽然得分高约 5 个百分点,但每次推理激活的参数是 Gemma 的 8 倍,存储需求高一个数量级。
专有模型在绝对分数上仍然领先。这是可以预料的。但差距正在迅速缩小,而 Gemma 4 的部署经济性则处于完全不同的维度。没有 API 成本,数据无需离开你的设备,没有供应商锁定。
诚实的结论
Gemma 4 在原始基准测试中并未击败 Claude Opus 4.6 或 GPT-5.2。任何声称相反的人都在误导你。
但是那不是正确的比较。正确的比较是:我能在自己的硬件上,用完全许可的许可证,零 API 成本地运行,最好的模型是什么?
在这个问题上,Gemma 4 是一个强有力的竞争者。虽然它在 GPQA 上比最佳专有模型低 7 ~ 8 个百分点,在 MMLU Pro 上低约 4 ~ 5 个百分点,但换来了专有模型永远无法提供的东西:完全的所有权和零边际推理成本。
对于许多实际应用来说,这种权衡不仅可以接受,甚至会是更优的选择。
为什么 Apache 2.0 改变了一切
之前的 Gemma 模型使用 Google 自定义的 Gemma 许可证。虽然相对宽松,但并非真正的开源。
Gemma 4 采用 Apache 2.0 许可证。与 Kubernetes、TensorFlow 和 Apache Spark 使用相同的许可证。
这是一个重大变化。Hugging Face 联合创始人 Clément Delangue 称之为“一个重大里程碑”。无使用限制,无报告要求,完全商业使用。你可以分叉、微调、按需部署。
对于构建 AI 产品的初创公司和企业来说:这消除了采用 Gemma 的最大障碍之一。你拥有自己的模型,拥有自己的数据,拥有自己的部署。
真实情况:Google 与中国在开源 AI 领域的竞争
让我给你战略背景。看看今天的 Arena AI 开源模型排行榜,前几名被中国模型主导:DeepSeek、Qwen 及其衍生品。美国的开源存在主要是 Meta 的 Llama 和 Nvidia 的 Nemotron。
Gemma 有 4 亿次下载,超过 10 万个社区变体。但在实际部署中(OpenRouter 使用数据可证),Gemma 一直落后于 Llama 和 DeepSeek。
Gemma 4 是 Google 的回应。31B 模型现在在 Arena AI 排行榜上排名第三。26B MoE 排名第六。两者都超过了比它们大 20 倍的模型。这不仅仅是一个模型发布,这是 Google 在宣告:我们正在争夺开源 AI 生态系统。这次是认真的。
本地运行
以下是实际操作方法。以下是如何在本地硬件上运行 Gemma 4:
首先,升级 llama.cpp:
brew upgrade llama.cpp
# 如果最新版本不可用,从 HEAD 安装:
brew install llama.cpp --HEAD
如果拥有 16GB RAM/VRAM(MacBook,大多数笔记本电脑):
llama-server -hf ggml-org/gemma-4-E4B-it-GGUF:Q8_0
如果拥有 24GB+ RAM/VRAM(MacBook Pro,RTX 3090):
llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q4_K_M
如果拥有 32GB VRAM(RTX 5090):
llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q8_0
31B 稠密模型的未量化权重可放入单个 80GB NVIDIA H100。量化版本可在消费级 GPU 上运行。
首日支持的生态系统包括:Hugging Face Transformers、vLLM、llama.cpp、MLX、Ollama、LM Studio、Unsloth、SGLang、NVIDIA NIM 等。
Gemma 4 的架构创新
几个突出的设计选择:
每层嵌入(PLE):E2B 和 E4B 模型使用了一个巧妙技巧。不为模型增加宽度或深度,而是为每个解码器层配备自己的小型嵌入表。这些表很大但仅用于快速查找。因此“有效”参数量(推理时实际运行的部分)远小于总参数量。E2B 有 5.1B 总参数,但有效参数仅 2.3B。
混合注意力:所有模型都交错使用局部滑动窗口注意力和全局注意力。局部窗口保持推理速度,全局注意力层(始终包括最后一层)保持对长上下文的深度理解。
正确实现的混合专家模型:26B MoE 使用 128 个专家,每个 token 激活 8 个,外加 1 个共享专家。推理时仅激活 3.8B 参数。这让你以 4B 参数模型的速度获得 26B 参数级别的智能。
原生函数调用:非事后添加。Gemma 4 支持结构化 JSON 输出和原生函数调用。这对于构建与外部工具和 API 交互的智能体至关重要。
可配置的思考模式:所有模型都支持内置推理模式。在系统提示中添加
<|think|>,模型会在最终答案前生成逐步推理。不需要深度推理时可禁用以获得更快响应。
Gemma 生态系统已成现实
数据说明一切。4 亿次下载,超过 10 万个社区变体。专业衍生版本包括:
- MedGemma:医学影像和临床报告生成
- DolphinGemma:海豚声音分析
- SignGemma:手语翻译
甚至有研究团队训练 Gemma 4 在 CARLA 模拟器中驾驶,使用多模态工具响应:模型通过摄像头观察道路,决定操作,并从结果中学习。这就是健康开源生态系统的样子。基础模型足够优秀,人们可以在其基础上构建真正新颖的应用。
我的真实看法
我写这篇文章时是持怀疑态度的。我曾对 Google 的开源承诺失望过。但这次的基准测试提升不是渐进式的。Codeforces ELO 从 110 跃升至 2150 是前所未有的。AIME 分数从 20.8% 跃升至 89.2% 不是营销噱头:这是一个根本不同的模型。
Apache 2.0 许可证消除了我最大的顾虑。硬件要求合理,生态系统支持从第一天起就非常完善。这是世界上最好的开源模型吗?31B 模型在 Arena AI 排名第三,不是第一。DeepSeek 和 Qwen 仍有强大产品。但 Google 现在确实具有竞争力。
对于构建本地优先 AI 应用、智能体工作流或设备端智能的开发者:Gemma 4 值得认真考虑。特别是 26B MoE 模型,是这个版本的黑马。开源 AI 战争变得有趣多了。
参考文献
- Google DeepMind. “Gemma 4: Byte for byte, the most capable open models.” DeepMind Blog, April 2, 2026. https://deepmind.google/blog/gemma-4-byte-for-byte-the-most-capable-open-models/
- Google AI for Developers. “Gemma 4 Model Card.” April 2, 2026. https://ai.google.dev/gemma/docs/core/model_card_4
- Hugging Face. “Welcome Gemma 4: Frontier multimodal intelligence on device.” April 2, 2026. https://huggingface.co/blog/gemma4
- 9to5Google. “Google announces open Gemma 4 model with Apache 2.0 license.” April 2, 2026. https://9to5google.com/2026/04/02/google-gemma-4/
- SiliconANGLE. “Google’s new Gemma 4 models bring complex reasoning skills to low-power devices.” April 2, 2026. https://siliconangle.com/2026/04/02/googles-new-gemma-4-models-bring-complex-reasoning-skills-low-power-devices/
- Engadget. “Google releases Gemma 4, a family of open models built off of Gemini 3.” April 2, 2026. https://www.engadget.com/ai/google-releases-gemma-4-a-family-of-open-models-built-off-of-gemini-3-160000332.html
- OfficeChai. “Google Releases Gemma 4 Open Models, Calls Them ‘Best In World’ In Their Category.” April 2, 2026. https://officechai.com/ai/google-releases-gemma-4-open-models-calls-them-best-in-world-in-their-category/
- Arm Newsroom. “Gemma 4 on Arm: Accessible, immediate, optimized on-device AI.” April 2, 2026. https://newsroom.arm.com/blog/gemma-4-on-arm-optimized-on-device-ai
- Constellation Research. “Google launches Gemma 4 open-source LLM family.” April 2, 2026. https://www.constellationr.com/insights/news/google-launches-gemma-4-open-source-llm-family
- OpenAI. “Introducing GPT-5.2.” December 2025. https://openai.com/index/introducing-gpt-5-2/
- Vellum AI. “GPT-5.2 Benchmarks (Explained).” December 2025. https://www.vellum.ai/blog/gpt-5-2-benchmarks
- NxCode. “Claude Opus 4.6 vs Sonnet 4.6: Complete Comparison Guide.” March 2026. https://www.nxcode.io/resources/news/claude-sonnet-4-6-vs-opus-4-6-complete-comparison-2026
- AI Tools Review. “Claude Opus 4.6 Review: Benchmarks & Rankings.” March 2026. https://aitoolsreview.co.uk/insights/claude-opus-4-6-deep-dive
- Maxime Labonne / Hugging Face. “Kimi K2.5: Still Worth It After Two Weeks?” February 2026. https://huggingface.co/blog/mlabonne/kimik25
- VERTU. “Open Source LLM Leaderboard 2026: Rankings, Benchmarks & the Best Models Right Now.” February 2026. https://legacy.vertu.com/lifestyle/open-source-llm-leaderboard-2026-rankings-benchmarks-the-best-models-right-now/
- Artificial Analysis. “MMLU-Pro Benchmark Leaderboard.” March 2026. https://artificialanalysis.ai/evaluations/mmlu-pro
- PricePerToken. “GPQA Leaderboard 2026.” March 2026. https://pricepertoken.com/leaderboards/benchmark/gpqa