译者:Carl Cui
国产 Kimi 模型的开发团队发现,ChatGPT、Claude、Gemini 和你所使用的其他所有 AI 模型,都存在结构性缺陷。
我先抛一个可能有点奇怪的问题:ChatGPT、Gemini、Claude、Grok、Llama 和 DeepSeek,这些架构的最深层有什么共同之处?它们都基于一个 2015 年做出的设计决策,而且直到现在,还没有人真正地质疑过这个决策。
2026 年 3 月 16 日,Kimi(月之暗面 LLM)背后的团队,发表了一篇题为 “Attention Residuals” 的论文,指出了现代所有 AI 模型中存在的一个结构性缺陷。
这不是什么基准测试的小把戏、新的数据集,或者更大的GPU集群。这关乎基础架构的改进。
这件事我们一直没碰,因为它一直运行得还可以。Elon Musk 转发了它。Andrej Karpathy,OpenAI 的联合创始人,评论说这篇论文“让我们意识到我们没有完全认真对待 Attention is All You Need 这个标题。” 当 Karpathy 这个级别的研究人员对一篇技术论文做出这样的评价时,就值得我们去了解 Kimi 团队到底发现了什么。
无人质疑的基础设施
你需要对当前 AI 模型如何运作有一个大致的了解,才能理解 Kimi 团队发现了什么。
像 ChatGPT 或 Claude 这样的模型不是单次的计算,它是由连续的处理步骤堆叠而成的,称为层,有时有几十层,有时有几百层。当你向这些模型发送消息时,它会先通过第一层,这一层处理原始的文字。第二层开始识别词语之间的关系。第三层识别结构。到了第十层,模型就能理解意图。到了第五十层,它就能用抽象的方式来推理意义。每一层都增加了深度。每一层都建立在之前的基础上。理论上,模型越深,它的思考就越复杂。
问题在于堆叠层数会带来的训练问题:当模型出错时,一个修正信号需要反向穿过整个堆叠,从最深的层一路回到第一层,来更新每一层的行为。但这个信号在传播过程中会减弱。让它穿过十层,它仍然足够强以发挥作用。但让它穿过一百层,它到达顶层时已经非常微弱,几乎无法推动任何改变。这种现象被称为梯度消失问题 the vanishing gradient problem,以前它对实际可以构建的神经网络的深度构成了重大限制。
2015 年,何恺明和他的同事们设计了一个巧妙的解决方案。他们实现了一个“捷径”,让原始输入可以直接跳过一层,和后续层的输出直接组合,而不是要求每一层都转换输入的数据。这个捷径称为残差连接 residual connection,因为它效果太好,成了后来所有神经网络的标准构件。你今天使用的每个模型,无一例外都依赖于它。
十年来无人注意的事情
残差连接 Residual connections 很好地解决了梯度消失问题 the vanishing gradient problem,好到以至于没人去研究其他可行的路径。十一年来,它们被视为一个已解决的问题,你只需要以此作为基础,而不需要审视它。
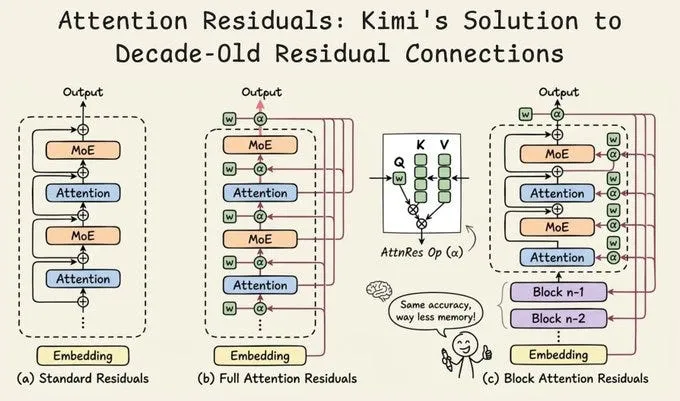
Kimi 团队发现了突破口。具体问题是这样:在标准的残差连接 standard residual connections 中,每一层接收所有先前层的总和,每个先前层对该总和的贡献相等。第一层和第五十层贡献一样大。第三层和第九十九层贡献也一样。这里没有过滤,没有选择,也没有判断哪个先前层的输出在当前这个时刻是有用的。这是一种盲目的累积:每一层都以相同的音量向不断增长的堆发出自己的声音。
一开始看起来好像还行。但随着模型层数变多,这个问题就会无限放大。每一层的隐藏状态,也就是每一层接收到的累积表示,会随着更多层级的加入而不断增长。而随着它的增长,每一层贡献出的信息在总量中的占比会变得越来越小。那些负责捕捉基础信息,比如词汇和语法的早期层级,会逐渐被覆盖掉。它们的信号在技术上仍然存在,但由于被严重稀释,模型几乎无法捕捉到它们。
与此同时,最深层面临相反的问题。要想对模型的最终输出产生影响,它们得产生足够大的信号,以从累积的噪音中脱颖而出。你走得越深,后续层必须变得越响亮,不是因为重要性增加,而是为了克服前面的噪音。
作者的截图
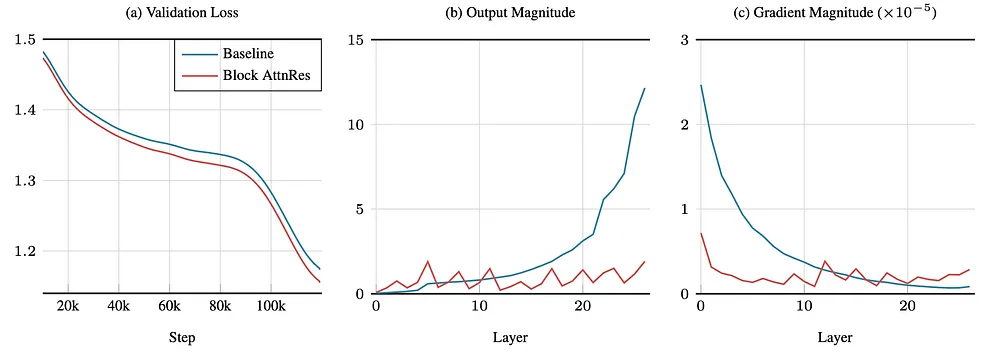
这篇论文直接证明了这一点:在标准模型里,输出幅度随深度单调增长。最后几层产生的信号特别大,不是因为它们在计算什么,而是因为信号累积过程中产生的一种副作用。
把它想象成一个没有指挥的管弦乐队。在早期排练中,当有十二个音乐家时,你能听到每一个乐器的声音。当你不断增加演奏者,五十个、一百个、二百个,开篇部分的低音提琴还在演奏,但它们已经被巨大的音量淹没。你再也分不清它们了。这正是 transformer 深层发生的事情。
同样的问题,已在另一个维度解决
这就是 Kimi 团队的洞察变得巧妙的地方。他们意识到他们以前见过这个问题,只是在不同的上下文中。
在 transformer 存在之前,AI 语言模型使用循环神经网络——RNN。这种模型是逐个字地处理文本,并且会维护一个“记忆状态”,这个状态在每一步都会更新。问题是:随着句子变长,前面单词的信息会被压缩到一个状态向量里,而且这个向量不断被覆盖。等到模型处理完一个长句子时,它实际上已经把句子的开头给忘了。这被称为健忘症问题 the amnesia problem,也让早期的聊天机器人因为无法维持对话而被嫌弃。

图片:Novy Bafouka
Transformer 架构,是在那篇具有里程碑意义的 2017 年论文《Attention Is All You Need》中提出的,它通过引入注意力机制解决了这个问题。不是将所有先前的单词压缩成一个模糊的状态,每个词都可以直接看到任何一个之前的词,并决定给它多少权重。这样检索就非常精确、灵活,并且依赖于上下文,确保了在压缩过程中不会丢失任何信息。
Kimi 团队的观察是精确的:标准残差连接 standard residual connections 在深度维度上所做的正是 RNN 在序列维度上所做的。每一层接收一个单个压缩状态,以相同权重混合之前的一切,并且没有能力回溯去选择性地提取某个特定的早期表征。
相同的结构。相同的问题。因此,潜在的解决方案可能也是一样的。
原文链接
Every AI Model Is Built on a 10-Year-Old Flaw. Kimi just fixed it