翻译:Transwan
校对:Carl Cui
引言:看上去确实有点不可思议,但作者
Manjunath Janardhan跑通了:通过per-expert disk streaming技术和turboquant-mlx-full在 16GB 的 Mac Mini 上成功运行起 122B LLM 量化版本。尽管 token 生成速度有限,但可以运行这件事本身就足够梦幻。这篇文章是作者TurboQuant系列文章的第 5 部分,展现出当前 AI 工程领域热点技术 ——expert Streaming和turboquant—— 的巨大潜力。以下是翻译全文:
Per-expert disk streaming 专家流式技术在 Mac 上运行了一个 122B 参数的混合专家模型 —— 这个模型的体积是 Mac RAM 的 3 倍。相同条件下输出结果能保持一致,不会触发操作系统内存交换机制,不需要 sysctl 调优。

图片由 Manjunath Janardhan 提供,通过 TurboQuant-MLX 专家流技术在 16 GB Mac mini 上运行的 122B 参数 LLM
我在一台拥有 16 GB RAM、价值 $599 的 Mac mini 上运行了一个 122B 参数的 LLM,并且可以生成连贯的内容。请注意,这不是我的笔误,这个模型是 Qwen3.5–122B-A10B,一个拥有 256 个专家的混合专家模型:在 BF16 格式下它的权重大约有 240 GB,使用 TurboQuant-MLX 量化到 3-bit 后,它在磁盘上仍然占用大约 54 GB 的空间,这个数字超过了这台机器所有 RAM 的 3 倍,按照以往的方式,它根本不可能在这台 16 GB 的 Mac 上运行。
但它还是跑起来了,这得益于一种名为专家流(expert streaming)的技术:它不再将所有 256 个专家都加载到内存中,而是直接从 SSD 中分页读取每个 token 实际使用的大约 8 个专家,通过使用一个小型缓存。模型文件在磁盘上占 54 GB,而常驻内存峰值大约在 9 GB。我并不是一上来就跑的 122B 模型,而是先从一个 35B 的模型开始验证这个想法,35B 模型可以适配进 4 GB 以下的内存,然后我又以相同的方式运行 122B 模型,想看看极限在哪里。
这篇文章主要围绕两点展开:这项在 35B 模型上得到验证、随后被推向 122B 模型的技术,以及从中得出的令人惊讶的结论,即对于稀疏 MoE 而言,“内存墙”实际上就是磁盘带宽墙。
这是关于 Apple Silicon 上 TurboQuant 系列文章的第 5 部分。在第 1 部分中,我将 Google 的 TurboQuant 改造用于 MLX 上的稠密模型权重压缩;在第 2 部分中,我将 TurboQuant 扩展到了混合专家模型(GPT-OSS-120B 在 64 GB Mac 上达到 44 token/sec,Qwen3.5–122B 达到 26.5 token/sec);在第 3 部分中,我添加了 KV 缓存压缩;在第 4 部分中,我设计了逐路径混合量化(per-path hybrid quantization),以便将 120B 模型塞进一台 48 GB 的 MacBook 中。每一部分都是通过量化技术来适配。而这一次则是通过磁盘带宽来适配的,并最终落脚在 16 GB 上——这是大多数人真正拥有的内存档次。
想在阅读时动手试试? 在任何 Apple Silicon Mac 上(16 GB 就足够了):
pip install "turboquant-mlx-full>=0.4.1"
python -m turboquant_mlx.stream.stream_generate \
model manjunathshiva/qwen3.5–122b-tq3 \
prompt "Explain why the sky is blue." \
max-tokens 128 - cache-budget-gb 4
完整的可直接复制粘贴的方案位于文末的自己尝试部分
为什么 16 GB 是最重要的档位
本系列的第 2–4 部分分别适配了内存更小的机器:64 GB,然后是 48 GB。但是对于 Apple Silicon 的设备来说,市面上绝大多数机器都是 16 GB,例如基础款 MacBook Air、14 英寸 MacBook Pro、Mac mini。如果一项技术需要 48 GB,它就无法在大多数人背包里的笔记本或书桌上的 mini 上运行。
而 16 GB 对大模型来说简直太少了,扣除操作系统和应用程序占用的内存后,你可能只有 10–12 GB 的可用空间。仅靠量化技术是不行的:即使采用激进的 3-bit 量化,一个 35B 模型在磁盘上也要占到 16 GB 空间,完全驻留内存时峰值约为 18 GB,这在你打开浏览器标签页之前就已经超过硬件限制了。122B 模型在 3-bit 量化下大约为 54 GB,想要完全驻留在 16G 内存中是天方夜谭式的。


Apple Silicon RAM 档位与可运行的最大 TurboQuant 模型对比。专家流技术(expert streaming)将 16 GB 这一行的极限从 ~20B 直接提升到了 122B。来源:Manjunath Janardhan 实验。
量化技术降低了模型大小。专家流技术则将模型大小与 RAM 彻底解耦,这也是将 122B 模型放进 16 GB 档位的关键技术。
两个模型
我使用了 Qwen 系列中的两个 MoE 模型 —— 它们采用相同的 qwen3_5_moe 架构,这点在后面很重要(一个加载器就能运行两者)。

”A3B”/“A10B” 是关键部分:每个 token 仅有 ~3B 和 ~10B 参数处于激活状态。这种稀疏性正是流技术奏效的根本原因,同时 256 个专家为 3-bit 量化提供了充足的冗余以保持输出内容的连贯性(这是第 2 部分的发现:高专家数量的 MoE 能够吸收 3-bit 噪声;而 32 专家模型则做不到)。
我使用标准的无数据 TurboQuant 3-bit 方案(Hadamard 旋转 + Lloyd-Max 码本)对两者进行了转换。在 64 GB 的 M4 Max 上,它们以完全驻留内存的方式运行,速度分别约为 60 和 26.5 token/sec。但 ~18 GB 和 ~55 GB 的峰值内存,是它们无法适配 16 GB Mac mini 的原因。
壁垒:仅靠量化无法适配 16 GB
你可能指望 MLX 的延迟加载(lazy loading)能拯救你:对权重进行内存映射,然后让操作系统按需将它们换入。我也曾这么指望,但是它行不通,理解其中的原因是理解后续所有内容的关键。
当你执行 load(…, lazy=True) 时,权重由 mmap 支持且未具体化(unmaterialized) —— RSS(常驻内存集)很小。但是在首次前向传播期间,会对每个专家张量执行矩阵乘法,而 MLX 必须将每个完整的 (256, …) 堆叠专家数组具体化到 Metal 缓冲区中才能运行其内核。在一个 token 处理完毕后,每一层的所有 256 个专家都已驻留内存,内存占用回到了 16+ GB,然后机器开始频繁交换内存页。延迟加载只是推迟了代价;它并不能避免代价。
因此,专家必须每次只显式加载少数几个,逐 token 处理,并在之后释放。这才是核心工作。
思路:通过流式技术只传输每个 token 需要的专家
MoE 路由器为每个 token 选取 256 个专家中的 8 个,这 8 个权重块是前向传播触及的唯一专家数据。其他所有内容,例如嵌入、注意力机制、归一化层、路由器、共享专家 —— 体积都很小且保持常驻内存。
因此:
- 保持非专家的“主干网络”常驻内存(几百 MB)。
- 对于每个 token,读取路由器的选择,并仅从磁盘换入这些专家的权重切片。
- 将最近使用过的专家保存在有字节预算的 LRU 缓存 中,这样热门专家就不必在每个 token 处理时重新读取。
- 绝不让完整的
(256, …)专家张量被具体化 materialize。
使 MoE 推理在计算上很廉价的稀疏特性(sparsity),在磁盘上同样有效。TurboQuant 将每个专家投影存储为一个沿专家轴连续排列的堆叠张量(stacked tensor),因此专家 e 是一个单一的连续字节范围,提取它只需一次已知偏移量和长度的 pread。第 2 部分中的解码核函数已经仅读取选定的 k 个专家,因此流式传输主要是:从换入内存的专家中组装一个小型的 (k, …) 堆栈,将路由索引重映射到局部位置,然后运行已有的核函数。数学运算则原封不动,这就是为什么相同条件输出内容与完全驻留内存的模型保持一致的原因(已验证:贪婪解码产生相同的 token 流;每步的最大绝对差值为 0)。

专家流式传输:驻留的主干网络(backbone)保留在 RAM 中;每个 token,路由器从 256 个专家中选择 8 个,并且只有这些连续的模型切片会通过
pread从磁盘读取到有字节预算的 LRU 缓存中,然后馈送到现有的 fused decode kernels。完整的 (256, …) 张量(tensor)从未被物化。来源:Manjunath janardhan 实验。
让我浪费了一天的陷阱:页缓存膨胀
第一个可用的版本可以实现流式传输,但 RSS 依然膨胀到了 12.5 GB,几乎和没有流式传输一样糟糕。MLX 管理的内存用量是健康的,大约 5 GB,那么另外 7 GB 去哪了?答案是 OS page cache。通过正常的 mmap I/O 读取 14+ GB 的专家切片时,macOS 将每个页面都缓存在了统一缓冲区缓存(unified buffer cache )中——这些页面是干净且可驱逐的,但在一台 16 GB 的机器上,12.5 GB 的 RSS 就是“能运行”和“转菊花(beachball)”的区别。修复方法涉及两个 macOS 特性:使用 F_NOCACHE(fcntl(fd, F_NOCACHE, 1))打开每个分片的 fd,这样 OS 就不会保留其页面;并使用 os.pread 代替 mmap 来读取切片。RSS 从 12.5 GB 降到了 ≈ MLX 托管内存的大小。F_NOCACHE 是流式读取器中最重要的一行代码——没有它,这一切都无法塞进 16 GB 的内存。
首个证明:3.9 GB 内存运行 35B 模型
在 122B 之前,先看 35B。在 基础款 Apple M4 Mac mini,16 GB 上测量,流式传输 3-bit 量化的 Qwen3.6–35B-A3B:

一个 35B 模型驻留在 3.9 GB 内存中,加载时主干网络的占用只有 0.45 GB。缓存大小是可调节的:更大的缓存 → 更高的专家命中率 → 更少的磁盘读取 → 更快的速度。在 2 GB 时,命中率约为 60%(约 3 token/sec);在 8 GB 时,命中率达到 91% 且约为 4.5 token/sec,依然剩余约 6.5 GB 可用内存。35B 模型证明了该技术行之有效且能保持连贯性。接下来的问题是:它能扩展到多高?
突破极限:在同一台机器上运行 122B 模型
我将完全相同的 stream_generate 指向了 Hugging Face 仓库 manjunathshiva/qwen3.5–122b-tq3。零代码修改——Qwen3.5–122B 与 35B 属于相同的 qwen3_5_moe 家族(也是多模态的,因此张量布局相同),因此加载器的专家路径原封不动地匹配了。
组大小 64 与 35B 的 32 相比没有区别——读取器是形状驱动的(shape-driven ),并且加载器会将模型真实的组大小传递给核函数。
首次运行,使用了保守的 —cache-budget-gb 1:
[stream] loaded in 138.6s | resident RSS=0.41 GB
Generation: 64 tokens, 0.65 tok/s | Peak memory: 6.0 GB
[stream] expert cache: hit_rate=0.0% disk_read=113.8 GB
它运行了。一个 122B 模型,在一台 16 GB 的 Mac 上,生成了一段连贯的瑞利散射解释(Rayleigh-scattering explanation)。驻留的主干网络占用为 0.41 GB,即使每层都有一个共享专家,非流式传输的权重也非常小。峰值内存为 6.0 GB。我原本担心 122B 的主干网络放不下,这种担忧完全是多余的。然后我试图通过将缓存提高到 8 GB 来加快速度——结果它崩溃了:
[METAL] Command buffer execution failed: Insufficient Memory
这是整个项目中最有趣的发现。
真正的上限不是 RAM——而是 Metal 的绑定内存上限
崩溃的原因并非总 RAM 不足(122B 模型峰值仅达到 6 GB),而是 Metal GPU 锁定内存上限。在 16 GB 的 Mac 上,GPU 只能锁定(wire)约 10.5 GB 的统一内存,而专家缓存存放在锁定的 MLX 内存中——因此,8 GB 的缓存加上约 5 GB 的基础内存占用,试图锁定约 13 GB 内存,直接冲破了上限。这得出了一条简洁的经验法则:mlx_peak ≈ 5 GB base + cache_budget。所以在 16 GB 的 Mac mini 上,缓存上限大约在 4–5 GB 之间。我使用 — cache-budget-gb 4 重新运行了一次:

在 16 GB mini 上运行 122B 模型。提升缓存增加了专家命中率(0% → 44.6%)和解码速度(0.65 → 1.08 tok/s),但缓存位于锁定的 GPU 内存中,因此 mlx_peak ≈ 5 GB + budget 会触及约 10.5 GB 的 Metal 锁定上限。Budget 4 是最佳平衡点;budget 8 会导致 OOM。来源:Manjunath Janardhan 实验。
Budget 4GB 是最佳平衡点:命中率从 0% 跃升至 44.6%(模型的“热门专家”被缓存——路由局部性比我预期的要好),每个 token 的磁盘读取量减半,解码速度超过了 1 tok/s,所有这些在 9 GB 峰值下实现,距离上限还有安全余量。核心数字约为 1 token/sec,这确实很慢——122B 模型每个 token 激活约 10B 参数,每步从 SSD 读取约 1 GB 数据,而在锁定上限的约束下,缓存只能覆盖 54 GB 模型的约 9%。现在磁盘带宽才是瓶颈,而不是内存,这种“慢”是人们可以接受的那种:122B 模型居然能在16 GB 的 Mac 上运行,而且限制因素是廉价、充裕的磁盘,而非稀缺、昂贵的 RAM。
两款模型,一台 16 GB 机器

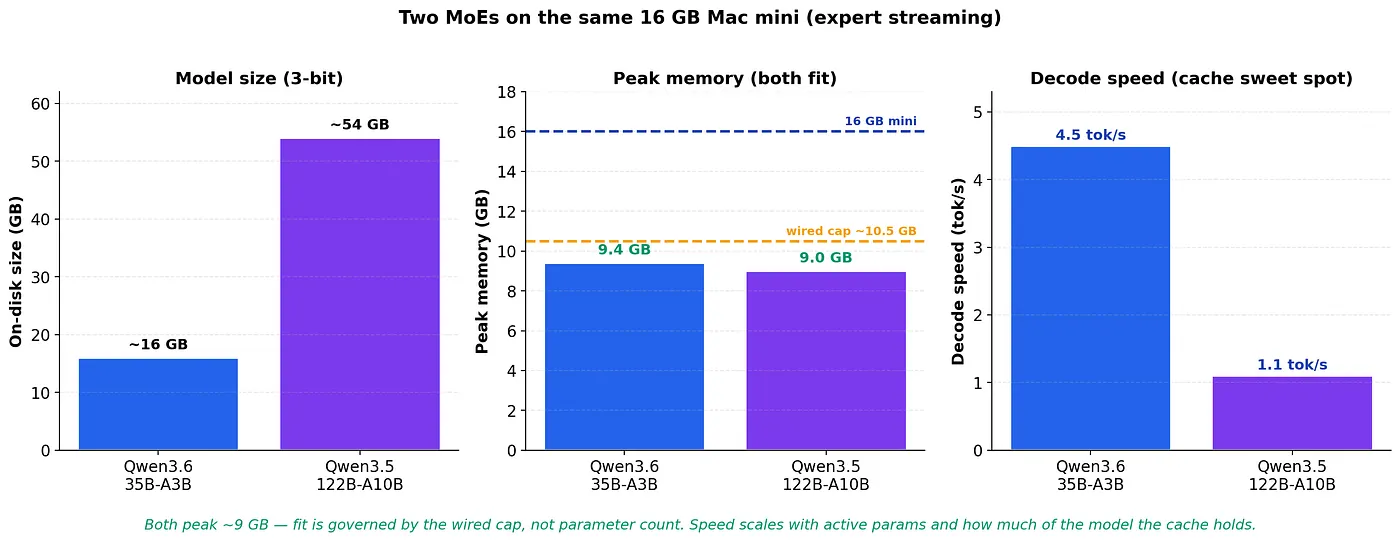
两款模型在同一台 16 GB Mac mini 上运行:35B 运行更快(活跃参数集更小,缓存覆盖了模型的一半);122B 受限于磁盘,速度约为 1 tok/s,但 16G 内存同样放得下。适配轻而易举,速度随活跃参数以及缓存能容纳模型的比例而变化。来源:Manjunath Janardhan 实验。
规律如下:适配受限于锁定上限和(微小的)骨干网络,而非参数量。这两款模型的峰值都在 9 GB 左右。速度由每个 token 的活跃参数以及缓存能容纳模型的比例决定,这就是为什么 122B 尽管和 35B 一样轻松装进内存,速度却慢了约 4 倍。

流式处理每个 token 只需移动模型的一小部分。122B 在 budget 为 4 时,每个 token 读取约 0.93 GB,不到其 54 GB 的 2%,然而这依然是吞吐量的限制因素。解码速度与每个 token 读取的字节数挂钩,而非模型大小。来源:Manjunath Janardhan 实验。
注意事项
速度 - 122B 模型约 1 tok/s(35B 模型约 3–4.5 tok/s)的体验是阅读节奏,而非实时聊天。如果按照其他方案根本无法运行模型时,流式处理就是正确的方式。如果你有一台 64 GB 的 Mac,完全可以让模型常驻在内存中。
锁定上限限制了缓存 - 在 16 GB 内存下,你无法在触发 Metal OOM 的情况下将缓存增长超过约 4–5 GB。你可以使用 sysctl 调高 iogpu.wired_limit_mb,但在 16 GB 的机器上这会榨干其他所有进程的内存,而“不调整 sysctl”正是此方案的意义所在。真正的修复方法(未来的工作)是将缓存的专家保存在常规 RAM 中,每个 token 仅锁定 8 个活跃专家,从而将缓存大小与锁定上限解耦。
SSD 读取 - 在 budget 为 4 时,122B 每个 token 读取约 0.93 GB。对于交互式使用来说还行,但也不是没有影响,在上限允许的情况下,更大的缓存对硬盘更友好,速度也更快。
思考模式模型 - 这两款 Qwen 模型在给出最终答案前都会输出一段 think 信息,因此请为它们设置宽裕的 — max-tokens(512 以上)。两者都不需要 — min-tokens 下限。
架构覆盖范围 - 该加载器当前针对的是 qwen3_5_moe 的专家布局。将其泛化到其他 MoE(GPT-OSS、Nemotron 的 latent-MoE)是下一步工作。按专家字节切片的原语是通用的,只有层路径的连接方式是特定于模型的。
亲自尝试
这里的所有内容都作为一个 PyPI 包和两个 HuggingFace 仓库发布,一台 16 GB 的 Mac 即可尝试。
# 1. 安装(纯 Python;Metal 内核在首次使用时 JIT 编译)
pip install "turboquant-mlx-full>=0.4.1"
# 2a. 122B(磁盘占用约 54 GB;速度约 1 token/sec;在 16 GB 内存上预算设为 4 是最佳选择)
python -m turboquant_mlx.stream.stream_generate \
-model manjunathshiva/qwen3.5–122b-tq3 \
-prompt "Explain why the sky is blue." \
-max-tokens 128 -cache-budget-gb 4
# 2b. 或者选择更快的 35B(磁盘占用约 16 GB;预算设为 8 时速度约 4.5 token/sec)
python -m turboquant_mlx.stream.stream_generate \
-model manjunathshiva/Qwen3.6–35B-A3B-tq3-g32 \
-prompt "Explain why the sky is blue." \
-max-tokens 512 -cache-budget-gb 8
每次运行都会报告常驻 RSS、解码速度 tok/s、专家命中率和总磁盘读取量。调高 —cache-budget-gb 可以提升速度(直到接近 Metal 绑定上限,在 16 GB 的 Mac 上约为 10.5 GB),调低则可以压缩 RAM 占用空间。
在 Python 中,加载器会为你替换专家层:
from turboquant_mlx.stream.loader import load_streaming
from mlx_lm import generate
from mlx_lm.sample_utils import make_sampler
model, tokenizer, cache = load_streaming(
"manjunathshiva/qwen3.5–122b-tq3",
cache_budget_gb=4,
)
text = generate(model, tokenizer, prompt="Why is the sky blue? Explain in detail.", max_tokens=128, sampler=make_sampler(temp=0.7), verbose=True)
print(cache.stats()) # hit_rate, resident_gb, bytes_read_gb
如果在某个我还没测试过的配置上发现了有趣的结果,比如 32 GB 的机器、外接 NVMe,或是不同的缓存设置?请在 https://github.com/manjunathshiva/turboquant-mlx 上提交 issue 或 PR。16 GB 这个层级还有很大的探索空间。
我的收获
稀疏性是一种内存技术,而不仅仅是计算技术 - MoE 的设计初衷是让你每个 token 只需计算网络的一小部分,同样的特性意味着每个 token 你只需将一小部分权重放在内存中,前提是你做好了相关的 bookkeeping 工作。流式传输正是将架构自身的承诺按字面意思兑现了。
在这种情况下,懒加载在 MLX 上是个陷阱 - “内存映射,按需加载”听起来似乎可以免费实现流式传输。但事实并非如此,第一次矩阵乘法就会将整个张量具体化(materializes),限制内存意味着必须显式加载专家并释放它们。
F_NOCACHE 是无名英雄 - 12.5 GB 和 4 GB RSS 之间的差异,仅仅是一个 fcntl 标志加上将 mmap 切片切换为 pread。在内存受限的机器上,控制操作系统页面的缓存与控制你自己的内存分配同样重要。
在 16 GB 的 Mac 上,RAM 并不是上限——Metal 的绑定内存上限才是 - 35B 和 122B 模型的峰值都在 9 GB 左右;真正的限制因素是约 10.5 GB 的 GPU 绑定上限,而缓存就存在于其中。了解了真正的限制因素后,改变了我调整一切的方式。
内存墙本质上是带宽墙的伪装 - 一旦模型实现了流式传输,“有多少 RAM”就不再是问题,取而代之的是“我的 SSD 有多快,以及缓存能容纳多少”。122B 模型轻松适应了 16 GB 的 Mac;它之所以“慢”,只是因为磁盘是瓶颈,而磁盘是很便宜的。这种视角的转换才是真正的成果,比任何单一模型都更重要。
参考资料
- TurboQuant 论文 https://arxiv.org/abs/2504.19874 — Zandieh, Han, Daliri, Karbasi (2025)。
- PyPI 上的 TurboQuant-MLX https://pypi.org/project/turboquant-mlx-full —
pip install "turboquant-mlx-full>=0.4.1" - HuggingFace 上的 Qwen3.5–122B-A10B-tq3 https://huggingface.co/manjunathshiva/qwen3.5-122b-tq3 — 122B 流式模型卡。
- HuggingFace 上的 Qwen3.6–35B-A3B-tq3-g32 https://huggingface.co/manjunathshiva/Qwen3.6-35B-A3B-tq3-g32 — 35B 流式模型卡。
- GitHub 上的 TurboQuant-MLX https://github.com/manjunathshiva/turboquant-mlx — 源码、问题反馈,Apache-2.0。
写在最后
- 订阅作者的 YouTube 频道,可以观看用直白英语讲解的 AI 视频:https://www.youtube.com/@AIBroEnglish
原文链接
A Qwen 3.5 122B LLM on a 16 GB Mac mini: MoE Expert Streaming with TurboQuant-MLX